R Commander에서 엑셀파일을 불러올 때가 있다. 이 때 사용하는 기능이다. 그런데 Rcmdr 2.7-x 에서 엑셀파일을 불러오는데 오류가 발생한다. 메뉴 한글화 담당자로서 이 상황을 설명하려고 한다.
Excel 데이터셋 불러오기 기능을 선택했을때 발생하는 오류: Windows용 Rgui.exe 사례
먼저 일반적인 번역 파일이 만들어지는 과정을 소개한다. Rcmdr 패키지의 소스 폴더에는 R-Rcmdr.pot 파일이 있다. 개발자가 작성하고 제공하는 메뉴 파일이 된다. 이 R-Rcmdr.pot 파일을 각국의 번역자들이 본인들 언어로 번역을 하게된다. 이 때 만들어지는 파일이, 한글의 경우 po 디렉토리 아래에 있는 R-ko.po 파일이며, 이 파일이 컴파일되어 R-Rcmdr.mo 파일이 inst > po > ko > LC_MESSAGES 디렉토리 아래에 만들어지게된다.
그럼, 이 오류는 왜 발생했는가를 설명한다. R-Rcmdr.pot 파일이 한글화 되는과정에서 만들어진 메세지 중의 하나, 그러니까 Excel을 불러올 때 사용되는 메세지에 오류가 있으며, 이 오류가 담긴 R-ko.po, R-Rcmdr.mo 파일이 개발자에게 전달되었으며, 이 소스 파일을 내려받은 한국어 사용자가 겪는 문제가 된다. 누구 실수인가? 번역 한글화를 담당한 본인의 실수이며, 개발자의 실수가 전혀 아니다. 개발자는 한글환경에서 사용하지 않기 때문에 문제를 겪지 않는다.
그럼, 메뉴 한글화 담당자인 본인은 왜 이런 실수를 저질렀는가? 나는 번역의 원칙 하나로 '최소 번역'을 취하고 있어, R-Rcmdr.pot 파일의 한줄 한줄 번역과정에서 원문을 복사해서 번역문에 붙여넣기를 자주 하게된다. 그런데, mac에서 메뉴 번역에 사용하는 도구인 poedit 프로그램이 원문 메세지를 command + c 로 복사하고 command + v 로 붙여넣는 과정에서, mac은 리눅스와 달리 이중따옴표(double quotation mark)의 모양이 영어 원문과 달리 한글형식으로 다소 변형되었던 것이다. 원문을 command +v 로 붙여넣기할 때 발생하는 현상인데, '붙여넣기' 대신 '붙여넣기 및 일치 비교 방식'으로 해야 이 현상이 발생하지 않는다.
어떻게 해결할 수 있는가? 첫째, 메뉴 한글화 번역자로서 사용자님께는 크게 미안한 이야기이지만, 개발자 john fox 교수에게 이 문제를 해결한 R-ko.po, R-Rcmdr.mo 파일을 전달할 생각은 없다. Rcmdr의 개발 버전이 업그레이드 되는 과정에서 번역자에게 전달될 새로운 R-Rcmdr.pot의 번역과정에서 점검하고, 수정하여 개발자에게 한글 번역 파일을 보내려고 한다. 둘째, 그럼 단기적으로는 어떻게 이 문제를 해결할 수 있을까. 이 글에 첨부된 소스파일을 사용하여 다시 Rcmdr을 다시 설치하기를 권한다. 1) 기존에 설치된 Rcmdr 패키지를 삭제한다. 2) 이 글에 첨부된 소스파일을 내려받아 로컬 설치를 한다. 예를 들어, install.packages("Rcmdr_2.7-2.tar.gz", repos=NULL, type="source") 등의 명령어 활용이 가능하겠다. 세째, 물론 마우스 사용없이 터미널 프롬프트에서 readxl 패키지를 스크립트문으로 사용하면 된다.
위에서 설명하고 제안한 것처럼 한글 환경에서 excel 파일을 R Commander 안으로 불러오려면, .po 파일을 수정해야 한다. 만약 이 과정이 번거롭고 또 자신이 없다면, 영문 환경에서 R Commander를 실행하면 excel 파일을 불러오는데 무리가 없다. 이후에 excel 파일로부터 불러온 데이터셋을 수정하고 관리하면서 새롭게 .RData 또는 .txt파일로 저장한 후 다시 한글 환경의 R Commander에서 추가 작업할 수 있다.
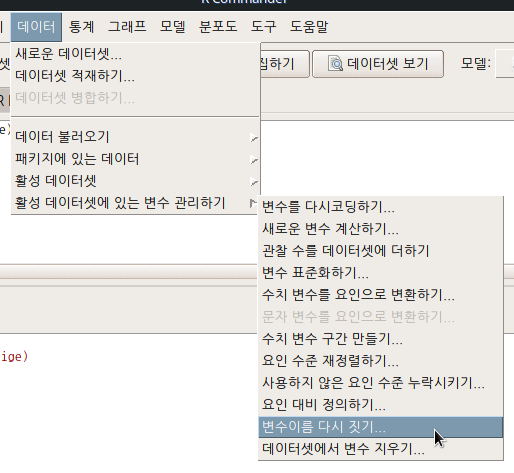
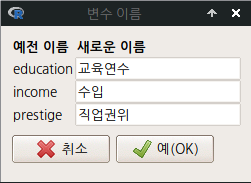
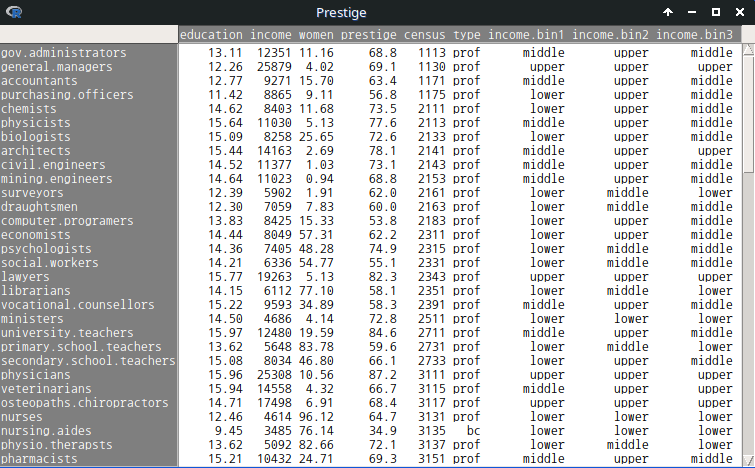
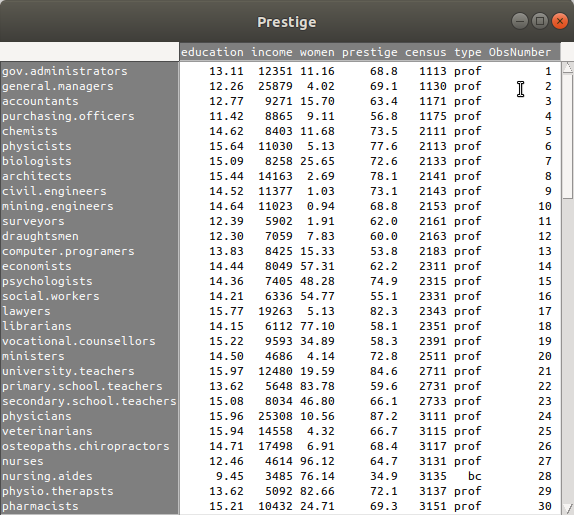
R Commander 화면에서 <데이터셋 보기> 버튼을 누르면, 다음과 같이 변수 이름이 바뀐 데이터셋 정보를 보게된다.
Linux 사례 (MX 21)
?names # base 패키지의 names 도움말 보기
# print the names attribute of the islands data set
names(islands)
# remove the names attribute
names(islands) <- NULL
islands
rm(islands) # remove the copy made
z <- list(a = 1, b = "c", c = 1:3)
names(z)
# change just the name of the third element.
names(z)[3] <- "c2"
z
z <- 1:3
names(z)
## assign just one name
names(z)[2] <- "b"
z
데이터 > 활성 데이터셋의 변수 관리하기 > 수치 변수 구간만들기... Data > Manage variables in active data set > Bin a numeric variable...
Linux 사례 (MX 21)
수치 변수를 촘촘히 연결된 연속형 변수라고 생각해보자. 선 그래프로 시각화 할 수 있을 것이다. 연속적인 값들을 구간으로 나누어 쪼개어 배치하는 기법이 필요할 수 있다. 흔히 연령을 연령대로 만드는 작업이 이것에 속한다.
구간을 만드는 작업창에는 몇 몇 검토 사항의 조건들을 묻는 내용이 있다. 1. 몇 개의 구간을 만들 것인가? 2. 구간 수준의 이름을 어떻게 정할 것인가? 3. 구간화 작업을 넓이로, 계산치로, 군집화로 할 것인가?
몇 개의 구간을 만들 것인가라는 질문에 답을 결정하려면, 아마도 이 수치형 변수의 요약적 특징을 미리 알고 있어야 할 것이다. 그리고, 구간화 작업에서 동일-넓이 구간이 기본 선택사항인데, 다른 선택을 하려면, 데이터에 대한 이해와 높은 분석적 통찰력이 요구될 것이다.
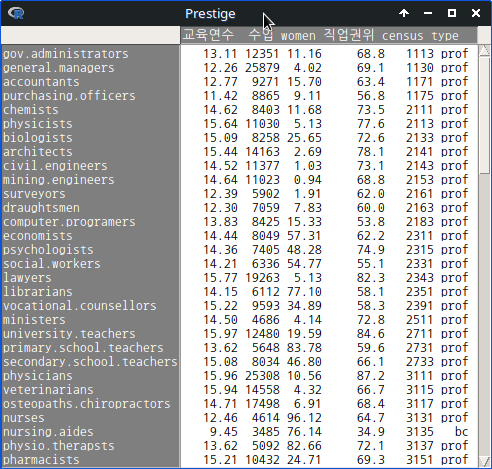
carData 패키지에 있는 Prestige 데이터셋의 수입(연봉)을 뜻하는 income 변수를 구간으로 쪼개자. income 변수는 수치형 변수이다. 102개의 income 변수의 사례 요약은 다음과 같다:
Linux 사례 (MX 21)
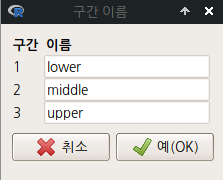
income.bin1, income.bin2, income.bin3 등 세개의 income 변수 구간화 작업을 하자. 구간의 수는 3개로, 수준 이름은 lower, middle, upper로 정하자. 구간화 기법은 bin1은 동일-넓이 구간, bin2는 동일-계산치 구간, bin3는 Natural breaks(K-평균 군집화에서)을 각각 선택하자.
데이터 > 활성 데이터셋의 변수 관리하기 > 수치 변수를 요인으로 변환하기... Data > Manage variables in active data set > Convert numeric variable to factor...
Windows 사례
수치 변수를 요인으로 전환해야 하는 경우가 흔하다. 남성을 1, 여성을 2로 입력한 엑셀 자료를 불러오는 경우, 1과 2를 요인으로 재지정해야 남성, 여성의 의미를 담은 변수로 활용할 수 있다. 일반적으로 이런 변수를 명목변수(nominal variable)이라고 하지만, R에서는 factor (variable)로 부른다. 간혹 요인분석에 익숙한 사용자가 factor와 factor analysis를 헷갈려하는 경우가 있기도 하다.
수치 변수인가? 요인 인가? 변수의 유형에 대한 이해가 필요한 이유는 실용적으로 볼 때, 시각화와 연결된 작업때문이다. 줄여 말하면, 수치 변수로 표현할 수 있는 시각화와 요인으로 표현할 시각화 기법이 다르다고 할 수 있다. 어려운가? 간단히 예를 들면, 히스토그램은 수치 변수의 시각화 기법이다. 그러나, 막대 차트는 요인의 시각화 기법이다. 수치 변수는 더할 수 있고, 요인은 셀 수 있다.
작업창에는 '다중 변수를 위한 새로운 변수 이름 또는 접미사: <변수와 똑같음>' 이라는 조건입력칸이 있다. 변수 이름을 덮어쓰면서, 바뀐 변수 유형을 기억하기도 하지만, 나는 흔히 _f를 추가한다. 원래의 수치 변수 옆에 _f가 붙어있는 요인을 만들어 그 차이를 기억하는 방식이다.
참고로, 간혹 다음의 오류 지시문 "수준의 숫자 ( ) (이)가 너무 넓습니다"이 아래 알림글에 나올 수 있다. 이것은 요인화로 만들어지는 수준의 갯수가 너무 많다는 의미이다. 그래서 요인 수준 이름을 일일이 넣을 추가 작업창을 R Commander에서 만들 수 없다는 뜻이다. 작업창의 요인 수준에서 "수준 이름 사용하기"를 선택 (기본선택사항)해서 이와 같은 오류 지시문이 나오는 경우, 그 아래에 있는 "숫자 사용하기" 선택을 하면 된다.
아래 출력창에서 airquality 데이터셋의 Month 변수와 month.f 변수를 비교해보자. Month 변수는 수치형 변수로서 최소, 평균, 최대 값을 갖고 있는 반면에, month.f 변수는 5에 31, 7에 31, 9에 30 등의 갯수를 갖고 있다.
Linux 사례 (MX 21)
?factor # base 패키지의 factor 도움말 보기
(ff <- factor(substring("statistics", 1:10, 1:10), levels = letters))
as.integer(ff) # the internal codes
(f. <- factor(ff)) # drops the levels that do not occur
ff[, drop = TRUE] # the same, more transparently
factor(letters[1:20], labels = "letter")
class(ordered(4:1)) # "ordered", inheriting from "factor"
z <- factor(LETTERS[3:1], ordered = TRUE)
## and "relational" methods work:
stopifnot(sort(z)[c(1,3)] == range(z), min(z) < max(z))
## suppose you want "NA" as a level, and to allow missing values.
(x <- factor(c(1, 2, NA), exclude = NULL))
is.na(x)[2] <- TRUE
x # [1] 1 <NA> <NA>
is.na(x)
# [1] FALSE TRUE FALSE
## More rational, since R 3.4.0 :
factor(c(1:2, NA), exclude = "" ) # keeps <NA> , as
factor(c(1:2, NA), exclude = NULL) # always did
## exclude = <character>
z # ordered levels 'A < B < C'
factor(z, exclude = "C") # does exclude
factor(z, exclude = "B") # ditto
## Now, labels maybe duplicated:
## factor() with duplicated labels allowing to "merge levels"
x <- c("Man", "Male", "Man", "Lady", "Female")
## Map from 4 different values to only two levels:
(xf <- factor(x, levels = c("Male", "Man" , "Lady", "Female"),
labels = c("Male", "Male", "Female", "Female")))
#> [1] Male Male Male Female Female
#> Levels: Male Female
## Using addNA()
Month <- airquality$Month
table(addNA(Month))
table(addNA(Month, ifany = TRUE))
데이터 > 활성 데이터셋의 변수 관리하기 > 변수 표준화하기... Data > Manage variables in active data set > Standardize variables...
Linux 사례 (Ubuntu 18.04)
활성데이터셋에 있는 수치형 변수들은 서로 다른 기준의 값들을 가질 것이다. 정수형 값도 있을 수 있다. 크기도 다를 수 있다. 만약 크기와 기준이 다른 수치형 변수들을 결합해서 분석 작업을 진행할 경우, 영향력 순위를 확인하는데 불편할 수 있다.
예를 들어서, 시험과목 중에서 어느 것이 난이도가 높은가를 알려면 평균점수를 확인할 것이고, 같은 점수라 하더라도 어느 과목점수가 더 높은가를 확인하려면, 이른바 상대평가를 하려면 척도 계산을 해야할 것이다. 변수 표준화하기는 척도 함수를 사용하여 상대화된 기준으로 사례 값을 재조정하는 기능이다. 대화창에서 수치형 변수를 선택하고 변수를 표준화하면, 기존의 변수명 앞에 Z가 붙는, Z.변수라는 새로운 표준화 값을 갖는 변수가 생성된다.
Prestige 데이터셋에서 교육연수(education)와 수입(income)이 직업의 권위에 대한 사회적 인식(prestige)에 어떤 영향을 미치는가에 대한 문제의식에 대한 통계학적 접근을 위하여 세개의 수치형 변수를 표준화하려고 한다.
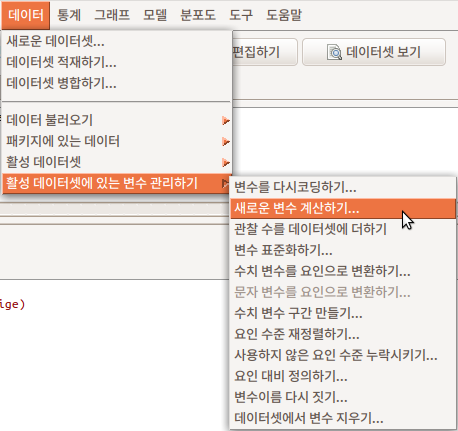
Data > Manage variables in active data set > Compute new variable...
Linux 사례 (Ubuntu 18.04)
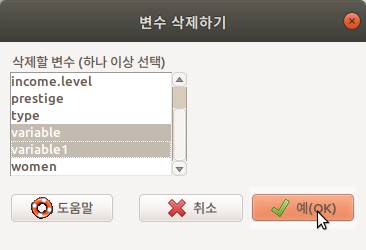
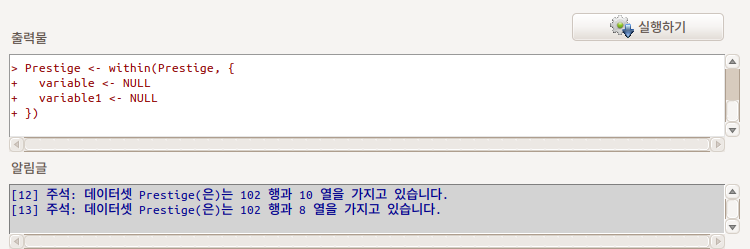
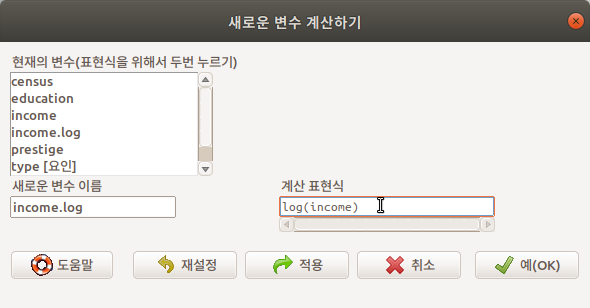
활성 데이터셋에 있는 변수들을 활용하여 새로운 변수를 생성하는 많은 방법이 있다. <Compute new variable...>은 일반적으로 수치형 사례를 갖고 있는 변수(들)을 사칙연산, log, 제곱근 등의 계산기법을 활용하여 새롭게 만드는 것이다. 계산에 의해서 새롭게 생성되는 사례들을 새로운 변수이름으로 저장할 수 있다. variable 이라는 추천된 변수 이름이 있지만, 사용자가 직접 지정할 수 있다.
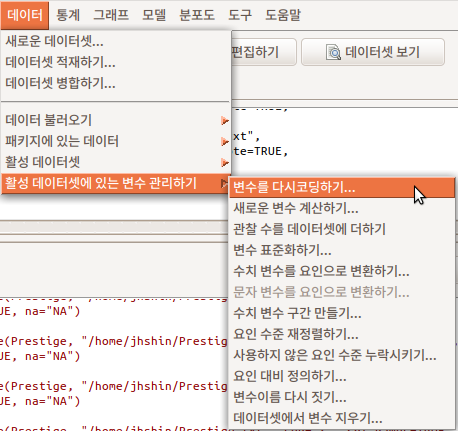
Data > Manage variables in active data set > Recode variables...
Linux 사례 (Ubuntu 18.04)
기존 변수를 이용하여 새로운 변수를 만들 수 있다. R Commander에서 이 기능은 일반적으로 수치형 변수를 요인형으로 바꾸는데 사용된다. <(각각의) 새로운 변수를 요인으로 만들기>에 선택이 되어 있는 것은 요인형으로 만드는 과정이다.
물론 수치형 변수의 사례값들을 다른 값으로 변환시킬수도 있다. 이 기능을 이해하기 위해서는 <"다시 코딩하기" 지시문 입력하기>에 대한 정확한 사용법을 익히는 것이 필수적이다. 초보자에게는 쉽지 않다. 하지만, 논리적으로 이해한다면 차후에 큰 어려움은 없을 것이다.
Linux 사례 (Ubuntu 18.04)
예를 들어 연령과 같은 수치 정보를 담은 변수가 있다고 하자.
10세 구간으로 바꾸려고 할 때, 10대, 20대, 30대, 40대, 50대, 60대, 70대 이상 등으로 사용할 수 있다. 때로는 65세이상으로 마지막 구간을 사용할 수 있다. 태어난 후 10세가 아닌 아이들을 배제시키기도 한다. 선거와 같은 정치적인 이슈에 대한 입장에서 20대 이상부터 시작하기도 한다. 이 경우 수치형 정보를 구간으로 바꾸어 요인화 시키는 과정이 필요하다.
때로는 소득과 관련하여 상-중-하 등의 3구간으로 나누는 것도 흔하다. 아래의 예와 같이 사용할 수 있다.
1:10000 = "low"
10001:20000 = "middle"
20001:max(데이터셋$변수) = "high"
else = NA
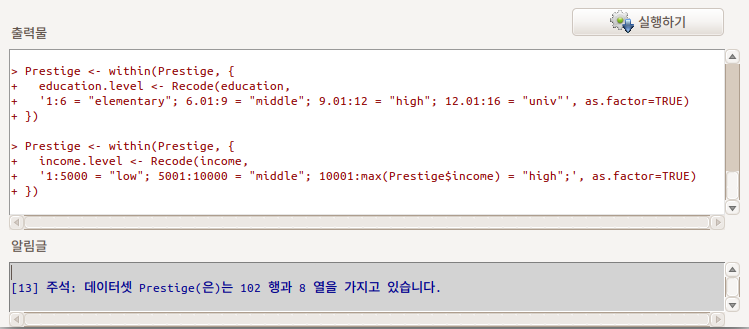
Prestige 데이터셋에 있는 수치형 변수 education의 구간을 만들어 사례값들을 넣고 요인형로 변수로 만들고자 한다. 아래와 같이 <'다시 코딩하기' 지시문 입력하기>에 입력할 수 있다. 1부터 6까지는 elementary로, 6.01에서 9까지는 middle로 , 9.01에서 12까지는 high로, 12.01에서 16까지 univ라는 구간명을 만들어 넣을 수 있다.
Linux 사례 (Ubuntu 18.04)
주의점으로, '다시코딩하기'지시문에 오직 큰 따옴표(" ")를 사용해야 한다. 작은 따옴표를 사용하면 알림글에 오류가 뜬다: 오류: '다시코딩하기'지시문에 오직 큰 따옴표(" ") 사용하기
Prestige 데이터셋에 있는 수치형 변수 education, income을 구간을 정해서 나누고 요인형으로 바꿔서 education.level, income.level 이라고 변수명을 만든 명령문의 출력 결과이다.