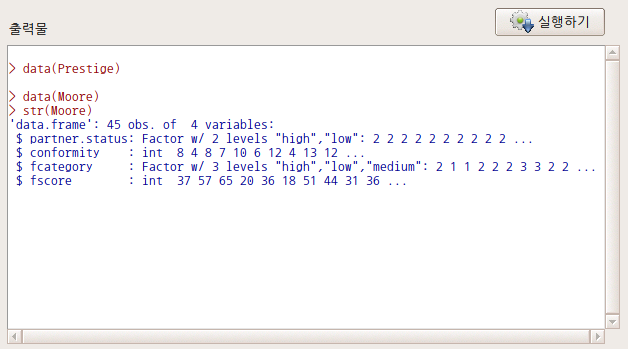
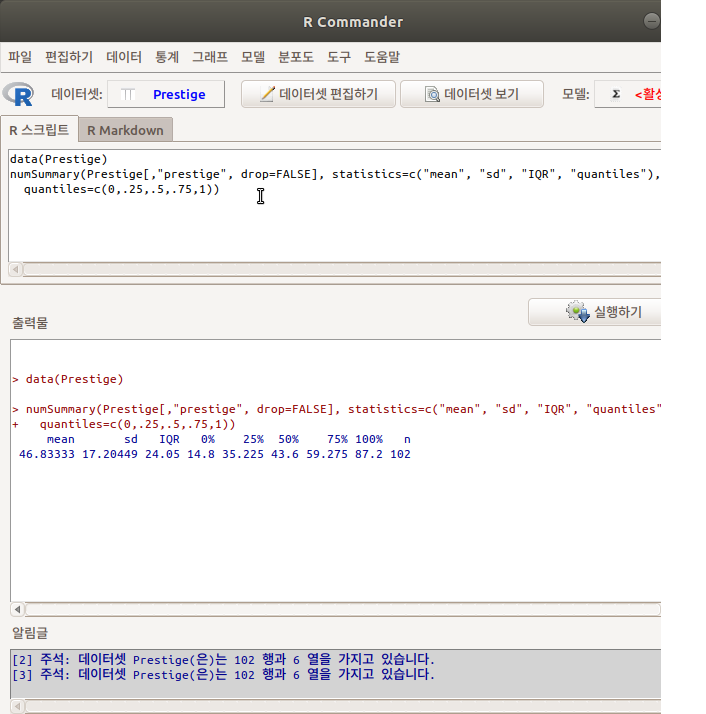
분석대상인 데이터셋에 요인형 변수가 한개 있거나, 하나도 없는 경우 분할표 메뉴의 오른쪽에 있는 <이원표>, <다원표> 기능은 불활성 음영 표시로 나타난다. 두개 이상의 요인형 변수가 있는 경우, 예를 들어 car 패키지에 포함된 Moore 데이터셋이 활성 데이터셋이 되는 경우 불활성 음영 표시가 사라진다.
Linux 사례 (MX21)
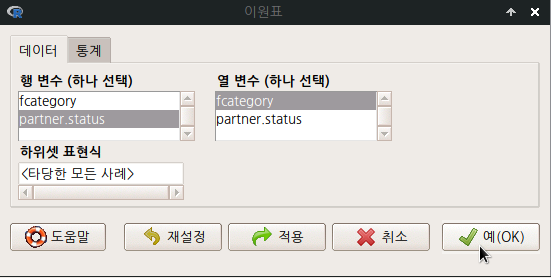
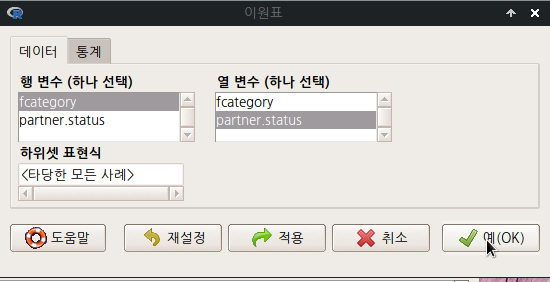
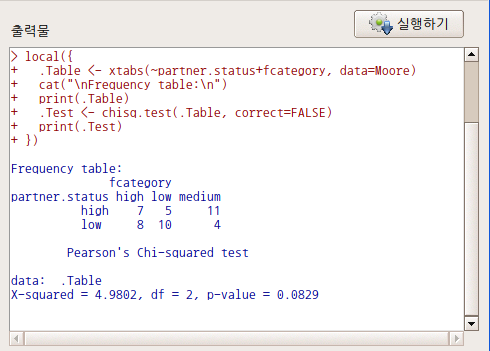
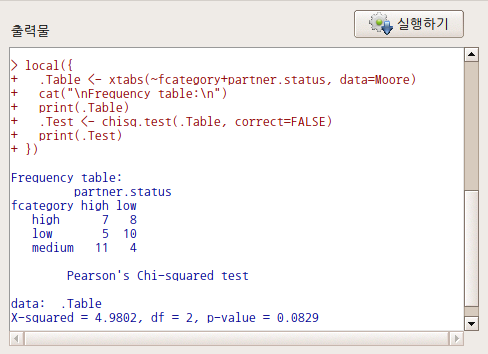
요인형 변수가 세개 이상 있는 경우, <다원표> 까지 활성화된다. 아래의 화면을 보면, partner.status, fcatetory 두개의 변수가 요인(factor)형이다. <이원표>는 활성화된 반면에, <다원표> 기능이 아직 활성화되지 않았다면, 요인형 변수가 두개 뿐인 데이터셋임을 간접적으로 알려준다.
통계 > 요약 > 상관 검정... Statistics > Summaries > Correlation test...
Linux 사례 (Ubuntu 18.04)
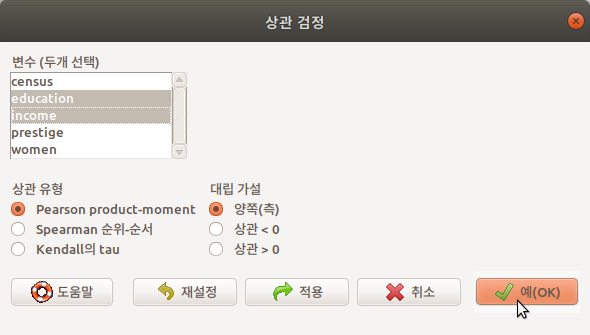
상관 검정은 두 변수를 구성하는 사례값들 사이에 어떤 방향의 관계성이 있는지를 통계학적으로 확인하고자 할 때 사용한다. 아래는Prestige 데이터셋에서 교육수준과 수입(연봉) 사이에 어떤 관계성이 있는지를 확인하고자 한다. education과 income 변수를 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (Ubuntu 18.04)
상관의 유형 중에서 Pearson product-moment (피어슨 적률상관), 대립 가설에는 양측이 기본으로 설정되어 있다. 이 설정을 바탕으로 상관 검증의 결과를 출력하면 아래와 같다:
Linux 사례 (Ubuntu 18.04)
cor.test() 함수를 활용한다.
?cor.test # stats 패키지의 cor.test 도움말 보기
## Hollander & Wolfe (1973), p. 187f.
## Assessment of tuna quality. We compare the Hunter L measure of
## lightness to the averages of consumer panel scores (recoded as
## integer values from 1 to 6 and averaged over 80 such values) in
## 9 lots of canned tuna.
x <- c(44.4, 45.9, 41.9, 53.3, 44.7, 44.1, 50.7, 45.2, 60.1)
y <- c( 2.6, 3.1, 2.5, 5.0, 3.6, 4.0, 5.2, 2.8, 3.8)
## The alternative hypothesis of interest is that the
## Hunter L value is positively associated with the panel score.
cor.test(x, y, method = "kendall", alternative = "greater")
## => p=0.05972
cor.test(x, y, method = "kendall", alternative = "greater",
exact = FALSE) # using large sample approximation
## => p=0.04765
## Compare this to
cor.test(x, y, method = "spearm", alternative = "g")
cor.test(x, y, alternative = "g")
## Formula interface.
require(graphics)
pairs(USJudgeRatings)
cor.test(~ CONT + INTG, data = USJudgeRatings)
통계 > 요약 > 통계표... Statistics > Summaries > Table of statistics...
Linux 사례 (Ubuntu 18.04)
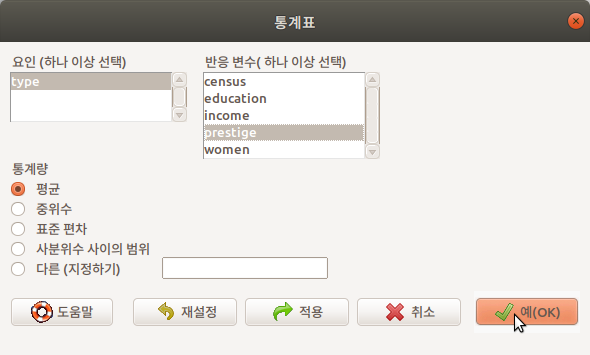
통계표(Table of statistics)는 요인(factor) 변수 유형별로 수치형(numeric, integer) 변수의 통계량을 계산하여 출력한다. Prestige 데이터셋에서 직업 유형의 type 변수를 요인에서 선택하고, 직업 유형별로 권위(prestige)의 통계량 중에서 기본 설정으로 선택된 평균값의 통계표를 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (Ubuntu 18.04)Linux 사례 (Ubuntu 18.04)
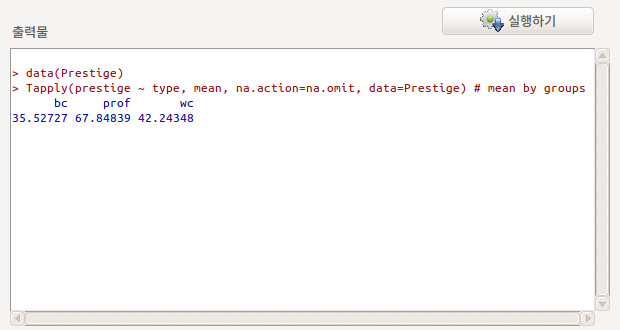
직업 유형(bc, prof, wc)별로 평균값을 계산하여 출력한다. 출력창을 보면 Tapply() 함수를 사용함을 알 수 있다.