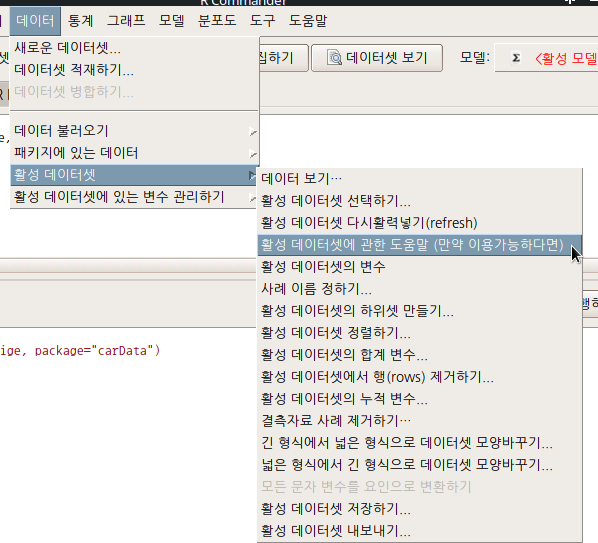
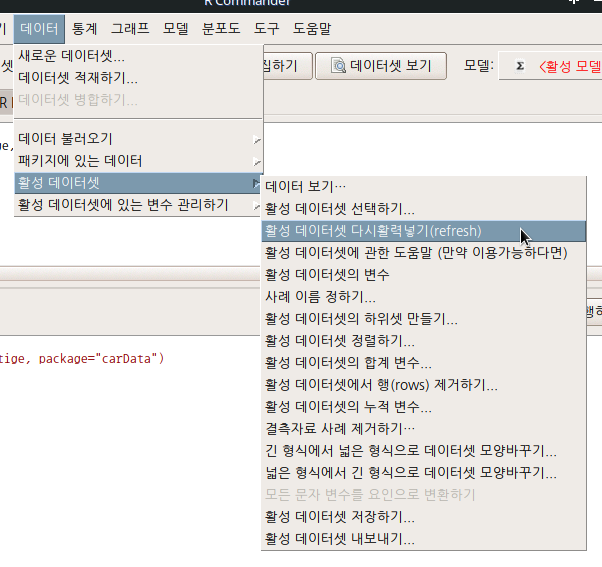
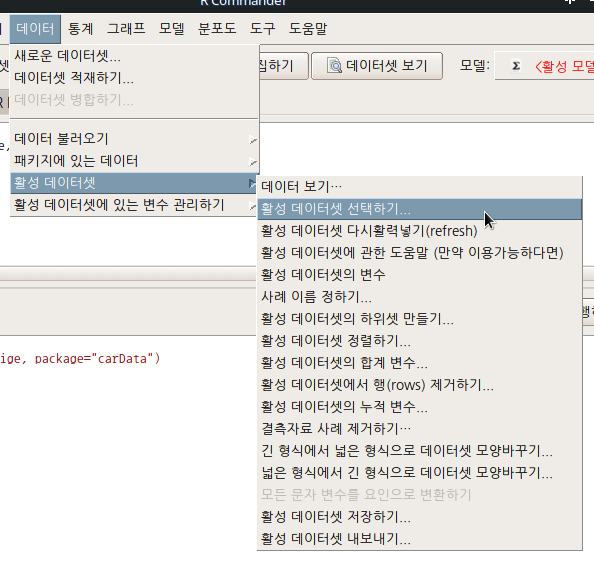
메모리에 올려진 데이터셋으로 작업하는 경우, 변수와 사례를 추가/삭제하는 경우가 빈번하게 발생한다. 줄여 말하면, 벡터를 만들거나 삭제할 수 있다. 이 경우, 작업이 진행된 객체의 '현재' 정보가 필요한 경우가 있다. 객체의 행과 열, 변수와 사례의 갯수를 업데이터해서 메세지로 알려준다.
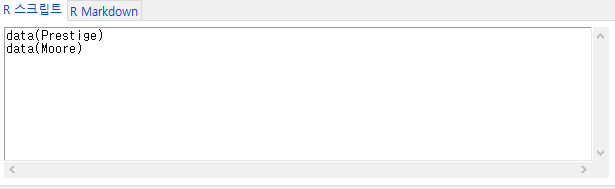
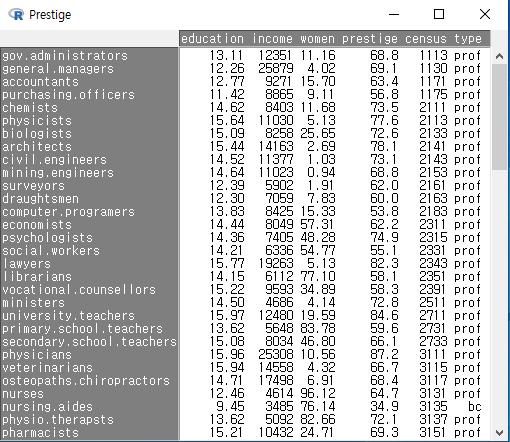
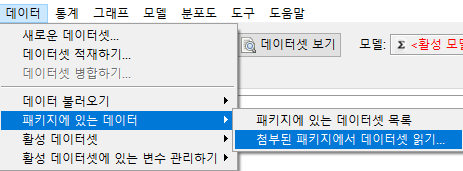
메모리로 불러온 데이터의 내부 값들을 볼 때 사용한다. 데이터프레임화 된 객체 전체를 보거나, 일부 변수들만 추려서 볼 수도 있다. carData 패키지에 포함된 Prestige 데이터셋을 사용하여 연습해보자. '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 기능을 선택하여 Prestige 데이터셋을 선택하자. 그러면, R Commander 상단의 '활성 데이터셋 없음'이 'Prestige'로 바뀐다. 이후 '활성데이터셋 > 데이터 보기...'를 선택하면 아래와 같은 메뉴창이 등장한다.
기본 설정에는 '모든 변수 포함하기'가 선택되어 있다.
Windows 사례
데이터셋의 크기가 작거나, 변수의 갯수가 적은 경우는 크게 무리 없이 '모든 변수 포함하기'를 이용할 수 있다.
Windows 사례
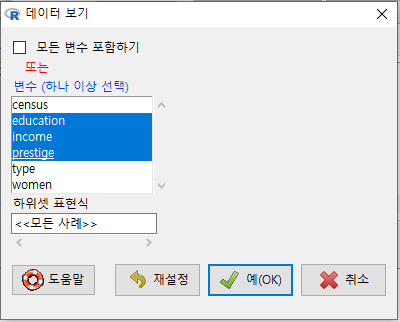
데이터셋에 대한 이해가 깊어지고, 분석의 대상의 명확해지면서 소량의 변수를 중심으로 데이터를 살펴볼 경우도 있다. 이 때는 '모든 변수 포함하기' 설정을 해제하고 필요한 변수들만으로 제한할 수 있다. Prestige 데이터셋에서 교육연수와 수입(연봉)이 직업의 권위에 대한 인식에 어떤 영향을 미치는가를 연구주제로 정했다고 하면, education, income, prestige 등의 변수로 제한할 수 있다:
Windows 사례 (10 Pro)Windows 사례 (7)
?showData # relimp 패키지의 showData 도움말 보기
data(mtcars)
showData(mtcars)
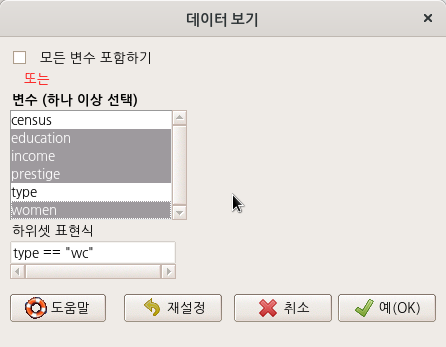
조금 난이도가 있는 고민을 해보자. 데이터셋 내부를 보고자 한다. 그러나, 데이터셋에 대한 기초적인 이해를 확보한 이후, 범위를 좁혀서 통찰력을 키우기 위하여 다양한 방식으로 데이터셋 내부를 보고자 할 수 있다. 몇 개의 변수를 선택하고, 또 요인형 변수의 어느 수준으로 제한된 범위 안에서 데이터셋 내부를 볼 수 있다. 아래 화면에서 원하는 변수를 선택하고, <하위셋 표현식>을 추가한 것을 볼 수 있다. type (직업 유형)에는 bc, prof, wc 라는 수준이 있다는 것을 미리 알고, white collar 직업군 내부의 정보를 보고자 type == "wc"로 제한하도록 하자.
Linux 사례 (MX 21)
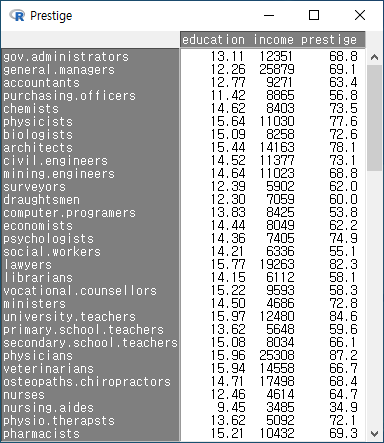
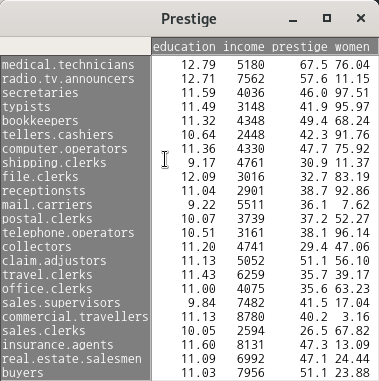
아래의 데이터는 Prestige 데이터셋에서 white collar 직업군으로 제한하여, education, income, prestige, women 변수의 사례를 출력한 결과이다.
Data > Data in packages > Read data set from an attached package...
Windows 사례
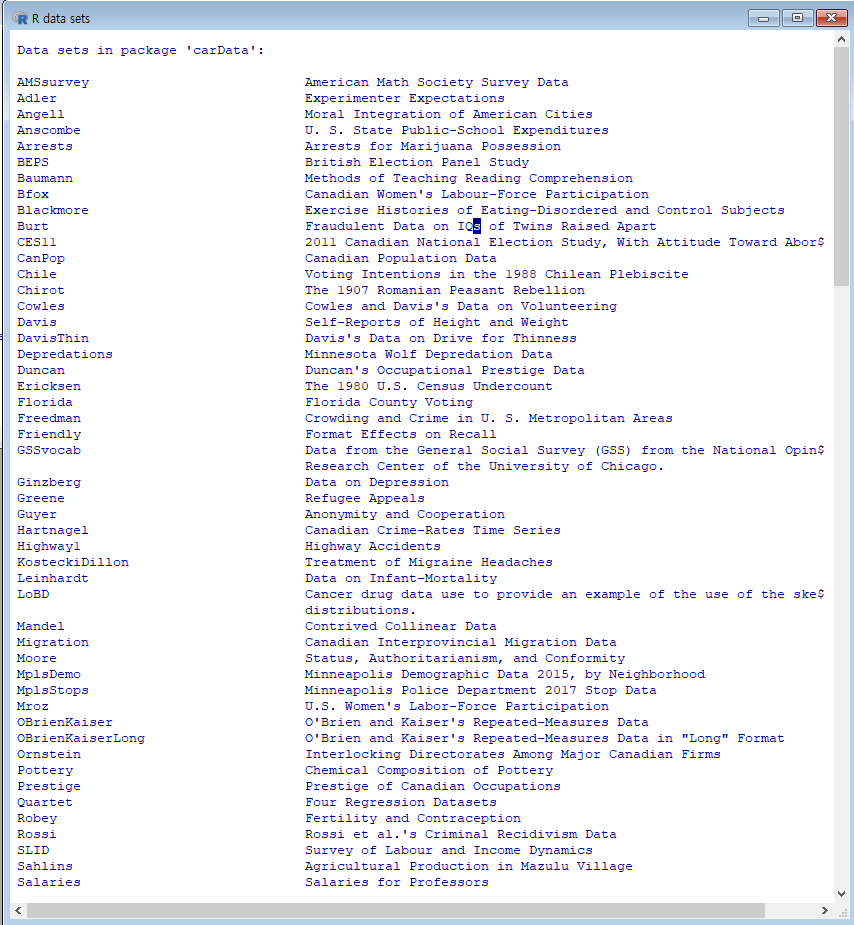
R에는 많은 예제 데이터셋이 있다. 대부분의 패키지들에 예제 데이터셋이 담겨 있다. R과 R Commander를 사용하는 과정에서 불러온, 다른 말로 하면 메모리로 호출된 패키지들에 데이터셋이 포함되어 있을 수 있다. 예제로 포함된 데이터셋을 선택하여 메모리 안으로 불러들일 때, 이 기능을 사용한다. 주로 통계 방법론이나 함수 사용법을 연습할 때, 주로 활용하게 된다.
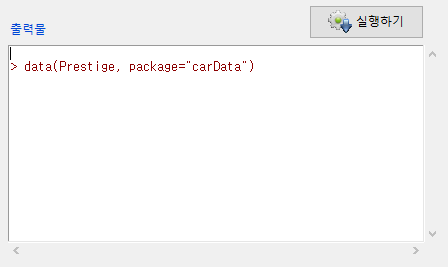
하나의 사례로서, carData 패키지의 Prestige 데이터셋을 선택한다.
Windows 사례
Windows 사례
출력 창을 보면, data() 함수가 사용됨을 알 수 있다:
data(데이터셋이름, package="패키지이름")
Windows 사례
?data # utils 패키지의 data 도움말 보기
require(utils)
data() # list all available data sets
try(data(package = "rpart") ) # list the data sets in the rpart package
data(USArrests, "VADeaths") # load the data sets 'USArrests' and 'VADeaths'
## Not run: ## Alternatively
ds <- c("USArrests", "VADeaths"); data(list = ds)
## End(Not run)
help(USArrests) # give information on data set 'USArrests'
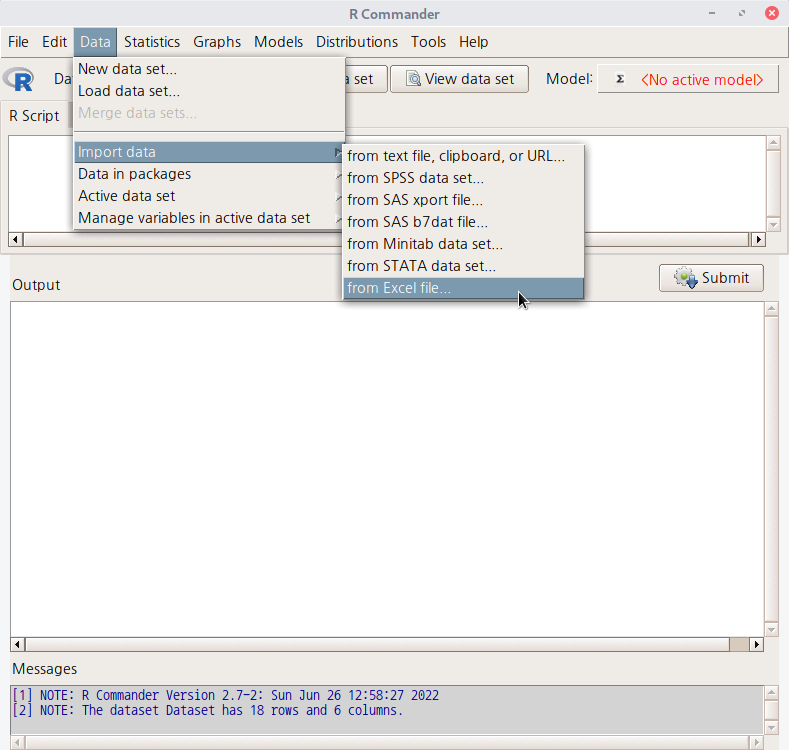
데이터 > 데이터 불러오기 > Excel 파일로부터… Data > Import data > from EXCEL file...
Linux 사례 (MX 21)Linux 사례 (MX 21)
Microsoft사의 Office 제품에 포함된 EXCEL은 광범위하게 사용되는 수치정보 관리 및 시각화 툴이다. 관리/재무 정보를 다루는 수많은 기업과 개인이 사용하기 때문에 R 사용자가 엑셀의 .xls, 또는 .xlsx 파일을 불러오는 요구는 매우 크다. 관심사가 크기 때문일까, R에서 EXCEL파일을 불러오기 위해서 개발자들이 만든 기여패키자들도 많다. R Commander에서 EXCEL파일을 불러오기 위하여 사용하는 외부 패키지도 변해왔다. 2019년 5월 현재는 readxl 이라는 패키지이다.
- EXCEL은 다른 통계분석툴과 달리 sheet 개념이 있다. 따라서 불러올 데이터의 객체화 과정에서 EXCEL 파일의 어느 sheet를 불러올 것인가를 선택할 수 있다. - EXCEL은 다른 통계분석툴과 달리 데이터 프레임화에 필요한 변수명에 대한 강한 규칙을 갖고 있지 않다. 따라서 R Commander의 기본 설정은 선택된 sheet의 첫 행의 정보를 변수 정보로 활용하는 것이다.
?readXL # RcmdrMisc 패키지의 readXL 도움말 보기
Rcmdr 2.7-x 의 한글 환경에서는 excel 파일을 불러오는데 오류가 발생한다. 아래의 문서를 참조할 수 있다.
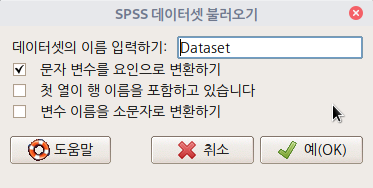
'데이터 > 데이터 불러오기 > SPSS 데이터셋에서...' 메뉴 기능을 선택하자. 아래와 같은 화면이 등장한다.
Linux 사례 (MX 21)
- 데이터셋의 기본이름은 Dataset으로 되어있다. 원하는 (영문)이름으로 바꿀 수 있다.
- 기본설정으로 클릭되어 제공되는 선택사항이 '(문자 변수를 요인으로 변환하기(Convert character variables to factors)'이다. 문자형 변수를 요인형 변수로 바꾼다는 것이다. 문자형을 요인형으로 바꾸는 것이 필요한가? 필요하지 않은가? 이 질문은 R을 이해하는 데 있어서 중요하다. 필요할 수 도 있고, 불필요하고 오히려 분석에 거추장스러울 수 있다. 하지만, R Commander에서 제공하는 대부분의 기능은 문자형을 요인형으로 만들어 처리한다.
SPSS라는 인기있는 GUI 사회과학 통계분석툴이 있다. 70년대 초반부터 발전해온 전산 통계툴이기 때문에, 대부분의 학자들에게 무척 친숙하다. SPSS 경험자들이 R을 배울 때 어색한 개념이 factor이다. R의 데이터 유형(Type) 중 하나인 factor는 흔히 '범주형(categorical)' 으로 SPSS 사용자들이 이해하고 있기 때문이다. 아울러 factor하면 요인분석에서 등장하는 개념으로 바로 넘어가는 경우가 흔하다.
요인형으로 바꾸는 이유는 시각화 작업과도 연관성이 크다. R에서 시각화되는 정보는 수치형과 요인형이다. 수치형은 연속형 자료로, 요인형은 이산형 자료로 시각화되기 때문에, plot()로 호출되는 방식이 크게 다르다. 문자형을 요인형으로 바꾼다는 것은 곧 시각화 준비를 마쳤다는 의미이기도 하다.
Linux 사례 (MX 21)
?readSPSS # RcmdrMisc 패키지의 readSPSS 도움말 보기
Dataset <- readSPSS("/home/jhshin/다운로드/foreign/inst/files/electric.sav",
rownames=FALSE, stringsAsFactors=TRUE, tolower=FALSE)
# 로컬 저장소에 있는 electric.sav 파일 불러오기 사례
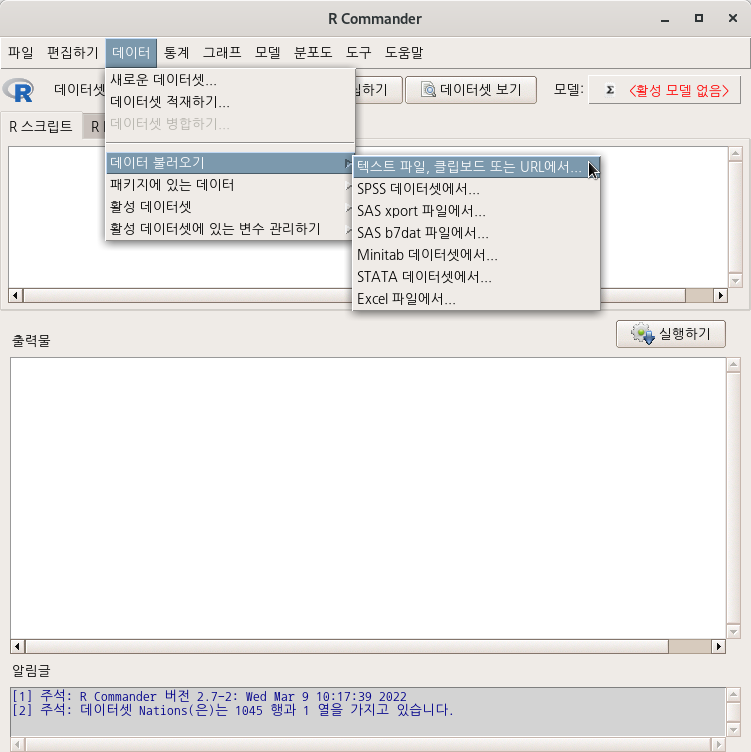
Data > Import data > from text file, clipboard, or URL...
Linux 사례 (MX 21)
개인적인 경험과 판단이지만, R에서 외부 데이터 파일을 불러오는 것을 초급자들은 너무 어려워한다. 쉽지 않다. 분석과 시각화 작업을 하기에 앞서서 자료 불러오기가 어려우니, 많은 사람이 쉬운 GUI 분석도구로 되돌아가려고 한다. read.table() 계열 함수가 어렵다.
R Commander는 이러한 불편함을 최소화하기 위하여 인자들을 쉽게 선정하도록 화면 구성이 되어있다. 하지만, 먼저 알아야할 것이 있다. R Commander에서 불러오는 객체, 다시말해 외부 데이터 파일로부터 불러올 대상은 반드시 데이터 프레임 형식을 취한다. 변수이름을 갖고, 엑셀과 같은 스프레드시트 형식으로 사례값들이 배열되어 있는 것만 GUI 메뉴로 작업할 수 있다. 만약, 데이터프레임 형식이 아니라면, 일반 콘솔 환경과 같은 조건에서 Command Line 작업을 해야한다.
Linux 사례 (MX 21)
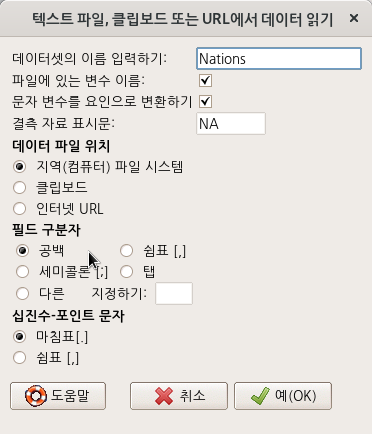
- data set의 기본이름은 Dataset이다. 원하는 것으로 이름을 바꿀 수 있다. 가급적 영문을 추천한다. 행여 다른 시스템에서 파일이름의 호환문제를 겪을 수 있기 때문이다. (위의 메뉴 창에서는 Nations라고 데이터셋의 이름을 변경했다.)
- 결측치 표시는 NA가 기본설정이다.
- 외부 파일을 불러올지, 메모리(clipboard)에서 불러올지, 외부인터넷 경로에서 내려받을 지를 선택할 수 있다.
- 필드 구분자를 선택할 수 있다. 사실, 필드 구분자가 초급자에게는 어렵다. 빈 공백, commas, 세미 콜론, 탭 등이 사용되기 때문에 혼란스러울 수 있다. 일반적으로 .txt로 되어 있는 것은 빈 공백, .csv로 되어 있는 파일은 comman인 경우가 흔하다. 하지만, 정확한 내부 규칙이 없기 때문에 어려개를 번갈아 선택해봐야할 수 있다.
- Decimal-Point의 경우, 한국은 미국스타일의 Period[.]를 관행적으로 쓰기 때문에 기본설정을 따르면 된다.
Nations라는 이름으로 불러온 데이터셋이 활성화되어 R Commander 에서 활용할 수 있는 환경이 시작된다.
사례를 하나 소개한다. libreOffice Calc에서 엑셀파일을 불러오고, 또 이것의 첫 시트를 clipboard에 복사하고, R Commander로 불러온다고 생각해보자.
- Locatioin of Data File에서 Clipboard를 선택하고,
- Field Separator에서 Tabs(탭)을 선택해야 한다. 기본설정을 바꿔야한다는 뜻이다.
한가지 유의해야할 것은 변수이름이 바뀌는 규칙이 있다는 점이다.
- R에서는 괄호를 변수이름에 넣을 수 없다. 앞뒤 괄호는 ..으로 바뀐다. '연락처(대표)'는 '연락처.대표.'로 바뀐다.
데이터 파일이 (어떤 규칙성에 의하여 성공적으로) 불러와지면, 상단의 R 아이콘 옆에 Data set:에 파란 색의 객체이름이 보인다. 기본설정이라면 Dataset이 될 것이다.
?read.table # utils 패키지의 read.table 도움말 보기
## using count.fields to handle unknown maximum number of fields
## when fill = TRUE
test1 <- c(1:5, "6,7", "8,9,10")
tf <- tempfile()
writeLines(test1, tf)
read.csv(tf, fill = TRUE) # 1 column
ncol <- max(count.fields(tf, sep = ","))
read.csv(tf, fill = TRUE, header = FALSE,
col.names = paste0("V", seq_len(ncol)))
unlink(tf)
## "Inline" data set, using text=
## Notice that leading and trailing empty lines are auto-trimmed
read.table(header = TRUE, text = "
a b
1 2
3 4
")