R에서 외부 자료를 불러올 때 기본 포맷으로 .csv를 사용한다. 그러나, 현실에서 많은 사용자들은 그냥 엑셀포맷 .xlsx를 이용하는 경향이 짙다. R사용자가 자료를 .csv로 보내달라고 하면, 귀찮아할 것이다.
보내온 엑셀파일을 여는 방법이 있다. R Commander에서도 기능을 제공한다. 그러나, 솔직히 불편하게 되어있는 점을 인정하지 않을 수 없다. Rstudio에서 'Import Dataset...' 기능을 사용하면, 쉽게 엑셀 자료를 R로 불러올 수 있기 때문이다. 엑셀자료를 불러오는데 걸림돌은 엑셀 시트의 내용이 구조화되어 있지 않거나, 또는 구조화되어 있어도 빈 공간들이 많은 경우이다.
여러개의 엑셀 파일 또는 시트에서 데이터셋을 많이 불러오는 경우가 아니라면, 적어도 단일 데이터셋을 불러오는 경우라면, '편법'을 이용할 수 있다. 마이크로소프트 오피스 또는 엑셀 프로그램을 갖고 있는 경우, 또는 유사한 스프레드시트를 갖고 있는 경우는 원하는 부분을 블록화할 수 있고, 또 복사와 붙이기가 가능하다. 줄여말하면, 클립보드 기능을 사용하면 R로 엑셀에서 데이터셋을 불러올 수 있다. 매우 손쉽다.
1. 엑셀 시트에서 R로 불러오고 싶은 부분을 마우스를 이용하여 선택(drag)하고, 복사한 다음에
R Commander의 메뉴 기반 사용법의 큰 특징은 활성 데이터셋에 관한 것이 될 것이다. 입력 창에 명령문을 입력하는 일반적인 방법과 달리 메뉴 기반 R Commander는 활성화된 데이터셋 하나만을 다룬다. (물론 데이터셋 병합하기는 두개 이상의 데이터셋을 필요로 한다)
Linux 사례 (MX 21)
아래 화면에 왼쪽에 R 아이콘이 있고, 그 옆에 '데이터셋: Prestige'이 보일 것이다. Prestige 라는 데이터셋이 활성화되어서 R Commander에서 사용할 준비가 되었다는 의미가 된다:
메뉴를 선택하면 다음과 같은 화면으로 넘어간다. 만들고자하는 데이터셋의 이름을 정하는 기능이다. Dataset 이라고 기본 설정되어 있다.
Windows 사례
새롭게 만들고자하는 데이터셋의 구조가 나타난다. 변수는 V1, V2, V3 등으로 자동적으로 일련변호화된다.
Windows 사례
변수 3개(V1, V2, V3), 사례 3개(1, 2, 3) 등으로 열과 행을 추가할 수 있다.
Windows 사례
셀(Cell)에 마우스를 놓고, 마우스의 오른쪽 버튼을 누르면 선택사항의 메뉴가 등장한다.
Windows 사례
Tcl package 'Tktable' must be installed first 라는 오류 메세지가 뜰 수 있다. 데이터셋을 만들기 위하여 추가적인 패키지가 필요하다는 뜻이다. (내가 지금 작업하는 우분투 18.04 리눅스에서 맞대고 있는 상황이다)
sudo apt install tktable*로 시스템에 추가 패키지를 설치하고, 다시 R 과 R Commander를 실행하면 테이블 형태의 새로운 데이터셋 (데이터프레임)을 만들 새로운 창이 뜬다. 행과 열을 추가하거나 지우고, 사례의 이름과 값을 넣고 지우는 방식으로 데이터셋을 만들 수 있다.
?editDataset # Rcmdr 패키지의 editDataset 도움말 보기
if (interactive()) editDataset() # Dataset 편집창 등장
데이터 > 활성 데이터셋의 변수 관리하기 > 요인 대비 정의하기... Data > Manage variables in active data set > Define contrasts for a factor...
Linux 사례 (MX 21)
요인형 변수의 특징을 수리적으로 다루기 위해서 행렬(매트릭스) 형식으로 재구성하는 경우가 빈번하다. 변수 내부의 기준 수준을 정하거나, 개별 수준들의 특징(사례 갯수, 거리)을 기준으로 행렬을 만드는데 활용되는 선택사항들을 결정한다. Prestige 데이터셋에는 직업 유형을 뜻하는 type 이라는 요인형 변수가 있다. <요인 대비 설정하기> 기능은 요인형 변수에만 해당된다. 다음의 화면에서 선택할 수 있다.
Linux 사례 (MX 21)
?contrasts # stats 패키지의 contrasts 도움말 보기
utils::example(factor)
fff <- ff[, drop = TRUE] # reduce to 5 levels.
contrasts(fff) # treatment contrasts by default
contrasts(C(fff, sum))
contrasts(fff, contrasts = FALSE) # the 5x5 identity matrix
contrasts(fff) <- contr.sum(5); contrasts(fff) # set sum contrasts
contrasts(fff, 2) <- contr.sum(5); contrasts(fff) # set 2 contrasts
# supply 2 contrasts, compute 2 more to make full set of 4.
contrasts(fff) <- contr.sum(5)[, 1:2]; contrasts(fff)
## using sparse contrasts: % useful, once model.matrix() works with these :
ffs <- fff
contrasts(ffs) <- contr.sum(5, sparse = TRUE)[, 1:2]; contrasts(ffs)
stopifnot(all.equal(ffs, fff))
contrasts(ffs) <- contr.sum(5, sparse = TRUE); contrasts(ffs)
데이터 > 활성 데이터셋의 변수 관리하기 > 사용하지 않은 요인 수준 누락시키기... Data > Manage variables in active data set > Drop unused factor levels...
Linux 사례 (MX 21)
carData 패키지에 있는 Prestige 데이터셋에는 type 이라는 요인형 변수가 있다. bc, prof, wc 라는 수준을 갖고 있다. blue collar, professional, white collar를 뜻한다. 블루칼라와 화이트칼라 그룹의 수입(연봉), 학력(교육연수), 직업권위를 뜻하는 income, education, prestige 라는 변수의 정보를 비교하고자 한다. 먼저 prof 수준을 데이터셋에서 제거해야 할 것이다.
아래 출력창에서 Prestige 데이터셋의 type, Prestige.sub1 데이터셋의 type 요약 정보를 비교해보라. Prestige 데이터셋의 type 변수에는 prof 수준을 가진 31개의 사례가 사라졌지만, prof 수준은 아직 남아있다.
Linux 사례 (MX 21)
Prestige.sub1의 type 변수에서 사용되지 않는 수준인, 다른말로 사례를 갖고 있는 않는 수준인 prof를 제거하자. 그래서 bc, wc 두개의 수준을 비교하는 정보를 만들고, 분석한다고 하자. <수준을 누락시킬 요인 (하나 이상 선택)>에서 type을 선택하고, 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
그리고 아래 화면에서 OK 버튼을 누른다.
Linux 사례 (MX 21)
Prestige.sub1 <- within(Prestige.sub1, {
type <- droplevels(type)
})
출력창에서 사용하지않는 요인 수준이 있는 변수정보와 누락시킨 이후의 변수정보를 찾아 비교해보라. type변수에 사례가 없는 prof 수준이 제거된 후 bc와 wc 두개 요인만 보일 것이다.
Linux 사례(MX 21)
?droplevels # base 패키지의 droplevels 도움말 보기
aq <- transform(airquality, Month = factor(Month, labels = month.abb[5:9]))
aq <- subset(aq, Month != "Jul")
table( aq $Month)
table(droplevels(aq)$Month)
데이터 > 활성 데이터셋의 변수 관리하기 > 요인 수준 재정렬하기... Data > Manage variables in active data set > Reorder factor levels...
Linux 사례 (MX 21)
carData 패키지의 Prestige 데이터셋을 이용해서 <요인 수준 재정렬하기> 기능을 사용해보자. Prestige 데이터셋에 있는 직업유형을 나타내는 type 변수는 bc, prof, wc라는 요인 수준을 갖고 있다. blue collar, white collar, professional 블루칼라, 화이트칼라, 전문직 등을 나타낸다. 그런데, bc, prof, wc는 순서가 있는 요인 수준이 아니다. 요인의 알파벳 순서대로 1, 2, 3 등이 부여된 요인 수준이다.
첫째로 bc, wc, prof로 수준의 순서를 바꿔보자. 먼저 type1으로 요인형 변수의 이름을 새롭게 정해보자.
Linux 사례 (MX 21)
bc에 1, wc에 2, prof에 3을 넣는다.
Linux 사례 (MX 21)
그렇다면, 둘째로 bc, wc, prof 순서를 정해놓고 각각 1, 2, 3을 지정해서 요인 수준을 정해보자. 정확히는 bc < wc < prof 순서를 정해놓고, 각각 1, 2, 3을 부여하는 것이다. type2라는 요인형 변수로 지정한다.
Linux 사례 (MX 21)Linux 사례 (MX 21)
str() 함수를 이용하여, type, type1, type2 변수의 구조를 살펴보자. 그리고 factor() 함수의 용례를 다시 살펴보라. levels, ordered 라는 인자가 의미하는 것을 알게될 것이다.
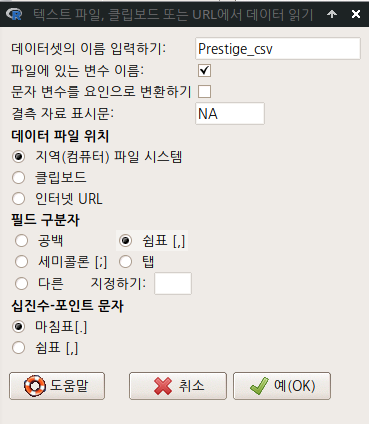
1. 불러올 데이터셋 파일의 이름은 Prestige.csv, 저장될 데이터셋 객체의 이름을 Prestige_csv라고 하자. 2. <문자 변수를 요인으로 변환하기>에 있는 클릭을 제거하자. 3. 필드 구분자를 <쉼표 [,]>로 선택하자. 4. 그리고 새롭게 열리는 디렉토리 창에서 Prestige.csv 파일을 찾아 선택하자.
Linux 사례 (MX 21)
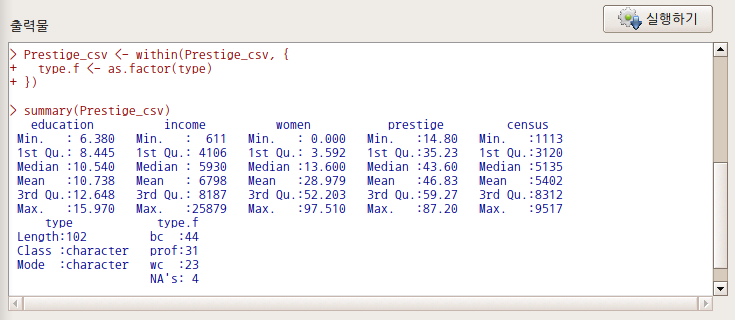
Prestige 데이터셋과 달리, Prestige_csv 데이터셋의 type 변수는 요인이 아닌 문자형이다.
Linux 사례 (MX 21)
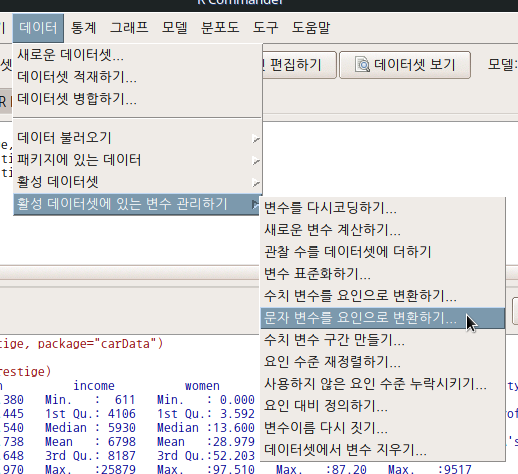
문자형 변수가 포함된 Prestige_csv 데이터셋이 활성화되면, <문자 변수를 요인으로 변환하기...> 기능이 활성화된다.
Linux 사례 (MX 21)
문자형 변수 목록에 type 변수가 보인다. <다중 변수를 위한 새로운 변수 이름 또는 접미사>에 변환시킬문자형변수.f를 넣고, 기존 type 변수와 비교해보자. 예(OK) 버톤을 누른다.
데이터 > 활성 데이터셋 > 모든 문자 변수를 요인으로 변환하기 Data > Active data set > Convert all character variables to factors
Linux 사례 (MX 21)
메뉴창의 기능이 비활성화되어 있다. 어느 데이터셋이 활성화되었음에도 이 기능이 비활성화되어 있다면, 이 데이터셋에는 문자 변수가 없다는 뜻이다. 예를 들어, carData 패키지에 있는 Prestige 데이터셋에는 문자변수가 없다. 이 경우, <모든 문자 변수를 요인으로 변환하기> 기능이 비활성화 상태에 있다.
str() 함수를 이용하여 Prestige 변수의 내부 구조를 살펴보면, 변수 유형에 int, num, factor가 있지만, chr (character)는 없다.
Linux 사례 (Ubuntu 18.04)
임의로 character 변수를 생성해보자. Prestige 데이터셋의 요인형 type 변수를 문자형으로 변환시킨후 R Commander의 인식 과정을 살펴보자.
Prestige$문자형변수이름 <- as.character(Prestige$요인형변수) 그리고, 다시 한번 str(Prestige)로 추가된 문자형 변수가 담긴 데이터셋의 내부 구조를 살펴보자. type.chr 라는 문자형 변수의 정보가 마지막에 보일 것이다. 입력창에 다음과 같이 입력한다:
Linux 사례 (Ubuntu 18.04)
활성화된 데이터셋에 문자형 변수가 포함된 경우, <모든 문자 변수를 요인으로 변환하기> 기능이 활성화된다.
Linux 사례 (Ubuntu 18.04)
strings2factors() 함수를 사용한다. 마지막 변수 type.chr의 변수 유형을 살펴보라.
Linux 사례 (Ubuntu 18.04)
?strings2factors # car 패키지의 strings2factors 도움말 보기
M <- Moore # from the carData package
M$partner <- as.character(Moore$partner.status)
M$fcat <- as.character(Moore$fcategory)
M$names <- rownames(M) # values are unique
str(M)
str(strings2factors(M))
str(strings2factors(M,
levels=list(partner=c("low", "high"), fcat=c("low", "medium", "high"))))
str(strings2factors(M, which="partner", levels=list(partner=c("low", "high"))))
str(strings2factors(M, not="partner", exclude.unique=FALSE))
17개의 변수에서 pre.(1, 2, 3, 4, 5), post.(1, 2, 3, 4, 5), fup.(1, 2, 3, 4, 5) 등이 15개의 변수를 구성하고 있다.
아래 메뉴창에서 <within-subjects 행(row) 요인 이름: >에 pre, post, fup을 포괄하는 phase를, <within-subjects 열(column) 요인 이름: >에 1, 2, 3, 4, 5를 포괄하는 hour를 넣자.
<최대 5수준까지 각 within-subjects 요인의 수준 이름을 지정하기> 아래의 행(row) 이름에 pre, post, fup을 넣고, 열(column) 이름에 1, 2, 3, 4, 5을 넣는다. 사례가 담길 곳에는 pre.1, pre.2, pre.3, pre.4, pre.5, post.1, post.2, post.3, post.4, post.5, fup.1, fup.2, fup.3, fup.4, fup.5 을 차례로 찾아 넣는다. 만약 잘못 입력되어 중복이름이 포함되면, 오류: 이중의 행(row) 수준 이름이 있습니다: 라는 오류문을 알림글에서 보게 될 것이다.
Linux 사례 (Ubuntu 18.04)
선택기능 메뉴창을 열고, OBrienKaiserLong1이라고 데이터셋 이름을 넣자. 그리고, <반응변수: >에 score라고 입력하자. carData 패키지에 있는 OBrienKaiserLong과 동일한 구조를 만들고 데이터셋 내부를 비교하기 위함이다.
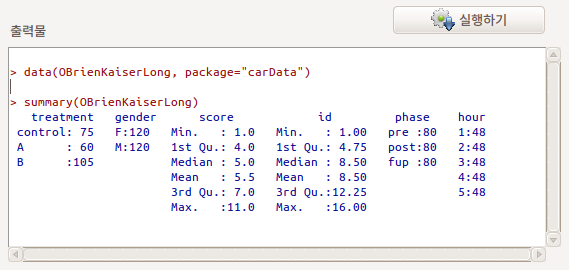
먼저 OBrienKaiserLong 데이터를 살펴보자. id 변수를 보면 개체 번호(subject)가 반복됨을 알 수 있다. phase 변수는 pre, post, fup가 hour 변수는 1, 2, 3, 4, 5가 반복된다.
Linux 사례 (Ubuntu 18.04)
전체 240개의 사례는 16개의 개체, 각 개체별 3개의 단계 (pre, post, fup), 각 단계별 5개의 시간대(1, 2, 3, 4, 5)의 score를 1 ~ 11까지 갖는다. 개체 1 ~ 5는 control 집단으로, 개체 6 ~ 9는 A 처방 집단, 개체 10 ~ 16는 B 처방 집단이며, 개체는 여성과 남성 각각 8명씩이다.
Linux 사례 (Ubuntu 18.04)
새롭게 만드는 변형된 데이터셋의 이름은 활성데이터셋이름Wide로 기본 설정되어있다. OBrienKaiserLong 데이터셋에서 개체를 나타내는 id 변수를 <Subject ID 변수(하나선택)>으로, 변화되는 값을 갖는 요인형 정보 hour, phase를 <Within-subjects 요인 (하나 또는 그 이상 선택)>으로, 변화되는 값인 score를 <상황에 의해 다양화되는 변수 (하나 또는 그 이상 선택)>에서 선택한다.
Linux 사례 (Ubuntu 18.04)
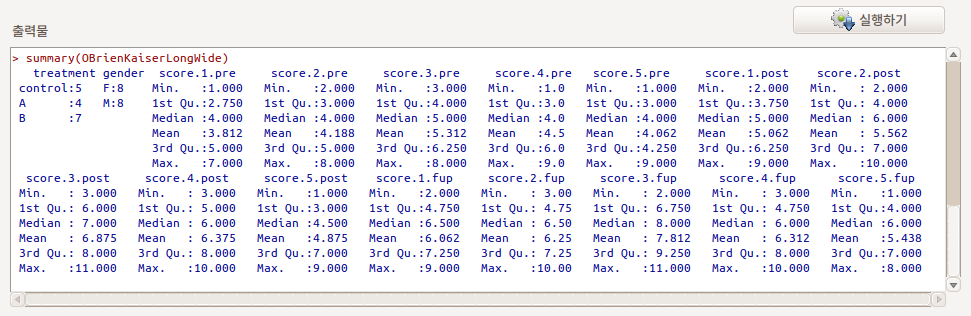
R Commander 맨 아래에 있는 알림글을 살펴보면, 주석: 데이터셋 OBrienKaiserLong(은)는 240 행과 6 열을 가지고 있습니다. 주석: 데이터셋 OBrienKaiserLongWide(은)는 16 행과 17 열을 가지고 있습니다. 라는 정보를 확인할 수 있다. treatment, gender 변수는 그대로 사용되지만, score별로 hour.phase의 요인 값이 표기되는 형식으로 변수가 15개 생성된다. score.hour(1~5).phase(pre, post, fup) 순서가 되겠다.
Linux 사례 (Ubuntu 18.04)
?ReshapeDatasetDialogs # Rcmdr 패키지의 ReshapeDatasetDiaglogs 도움말 보기