통계 > 적합성 모델 > 선형 모델...
Statistics > Fit models > Linear model...
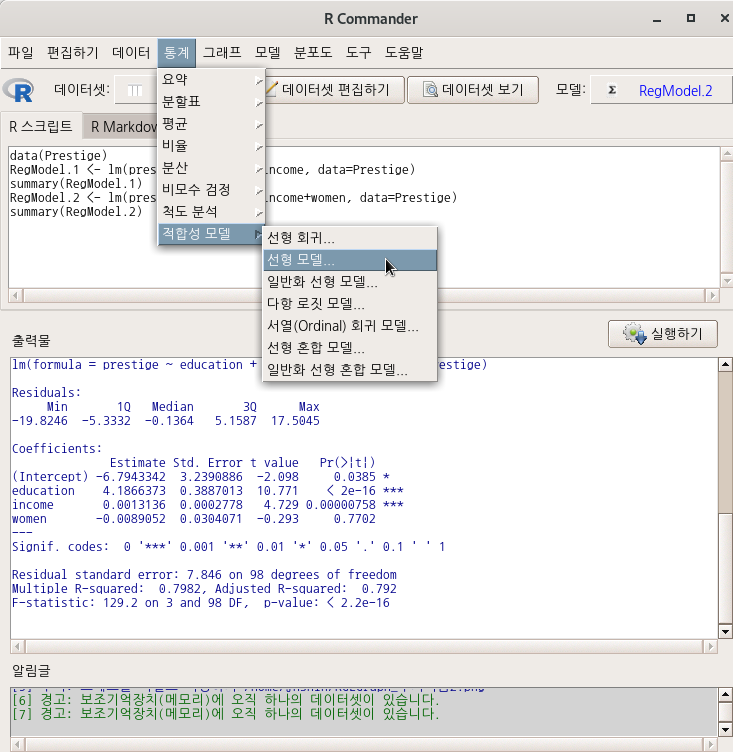
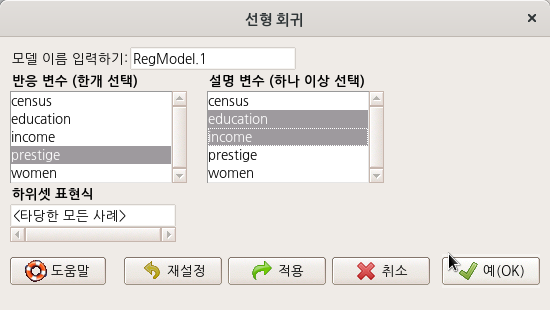
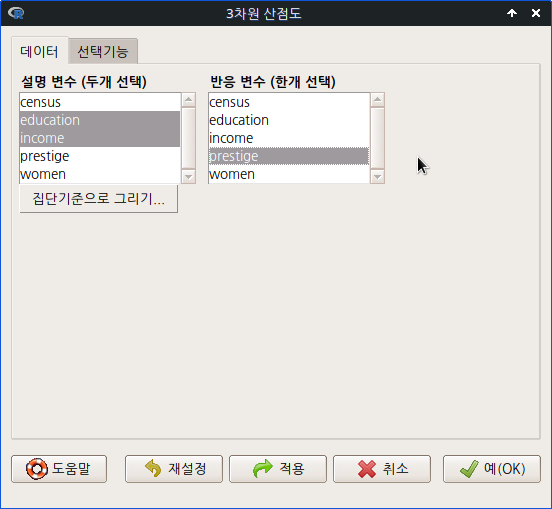
아래와 같은 <선형 모델> 선택 창에서 변수들을 선택할 수 있다. ‘통계 > 적합성 모델 >선형 회귀...‘기능의 <선형 회귀...>창과 달리 선택할 수 있는 변수에 'type [요인]'이 추가되어 있다.
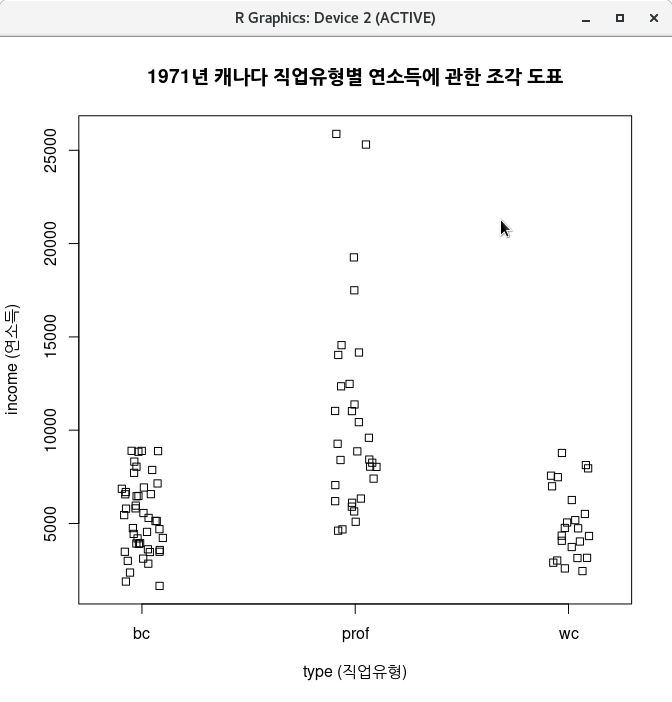
carData 패키지에서 제공되는 Prestige 데이터셋에는 요인형 변수 type이 포함되어 있다. <선형 모델> 기능에는 요인형 변수를 함께 넣어서 계산할 수 있고, 표본을 모집단 크기에 비율적으로 맞추고자 사례 값에 가중치를 넣어서 계산하는 <Weights> 선택 기능이 있다. 그리고 변수를 선택하는 것을 뛰어넘어 변수들 사이의 관계성을 수식화 할 수 있는 <모델 공식> 기능이 포함되어 있다.
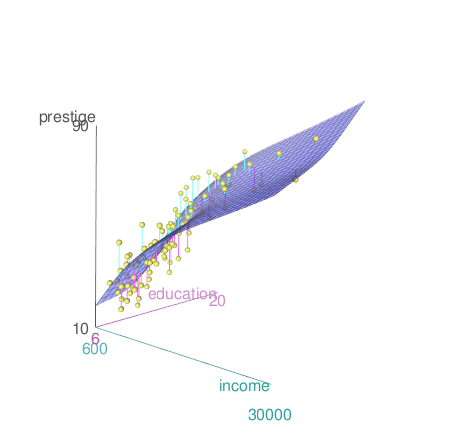
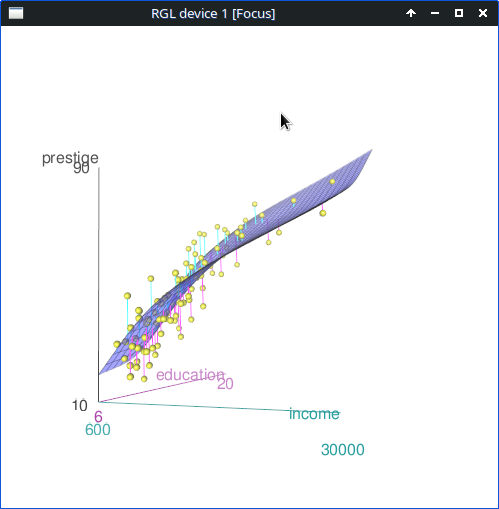
아래 <선형 모델> 창은 위의 모델 구성식과는 다른 방식을 제안한다. 직업의 사회적 권위 (prestige)에 대한 education + income + women + type 의 영향력을 계산하는 것이 아니라, education + log(income)의 결과와 type의 관계가 prestige 변수에 미치는 영향력을 계산하는 식이다.
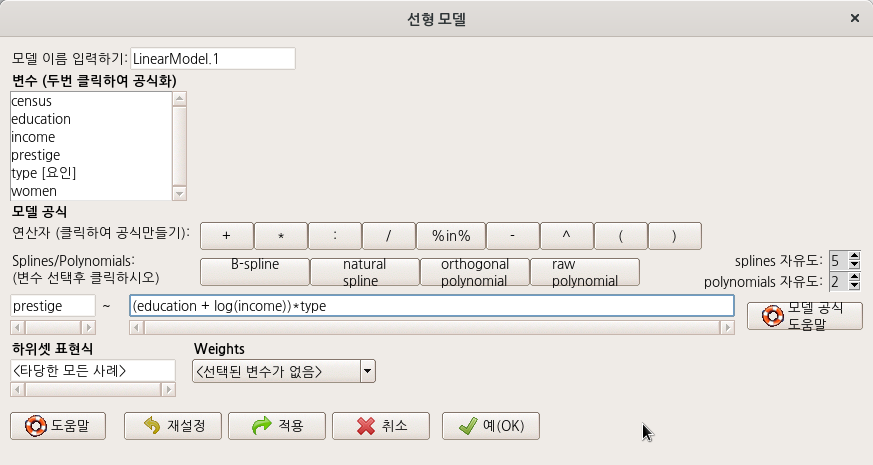
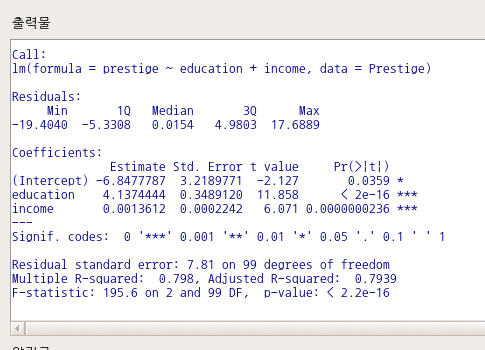
LinearModel.1 <- lm(prestige ~ (education + log(income))*type, data=Prestige)
summary(LinearModel.1)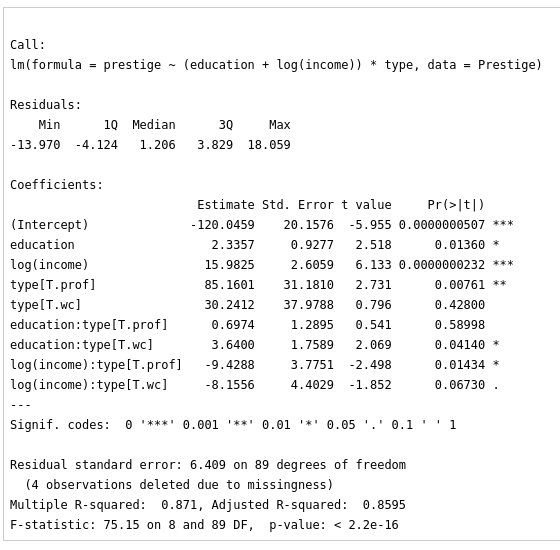
'Statistics > Fit models' 카테고리의 다른 글
| 5. Ordinal regression model... (0) | 2022.06.24 |
|---|---|
| 6. Linear mixed model... (0) | 2022.06.23 |
| 4. Multinomial logit model... (0) | 2022.03.09 |
| 3. Generalized linear model... (0) | 2022.03.09 |
| 1. Linear regression... (0) | 2022.03.07 |