R이 시작될 때, datasets 패키지가 자동으로 호출된다. 따라서 R Commander를 실행할 때, datasets 패키지는 첨부 패키지화되어 메뉴창을 통해서 내부 데이터셋을 찾고 불러올 수 있다.
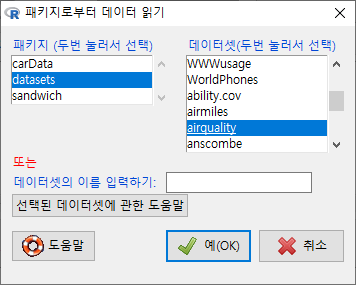
메뉴창에서 순서대로 데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기... 를 선택하면 다음과 같은 창이 등장한다.
Windows 사례
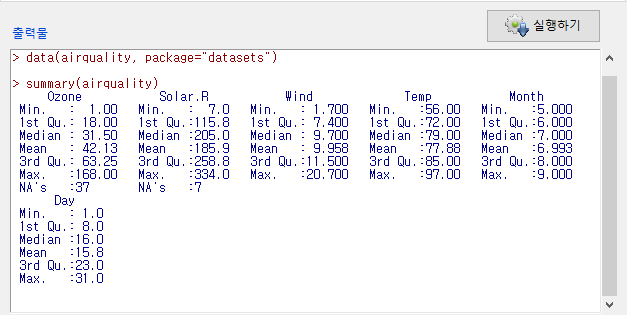
출력창을 보면, airquality라는 데이터셋에는 6개의 변수가 있고, 각 변수는 수치형 정보를 담고 있다.
Windows 사례
Month 변수는 최소 5에서 최대 9로 값이 있는데, 정확히는 5월부터 9월까지일 것이다. 한달 한달을 뜻하는 월(month)은 5월이 9월보다 크다고 할 수 없고, 5월, 6월, 7월, 8월, 9월 등으로 개체화되어 분리된다. 다시 말하면, 요인형 변수가 되어야 한다는 뜻이다.
그럼 왜, airqualty 데이터셋의 Month 변수는 수치형으로 되어 있을까. 원자료를 R의 데이터셋으로 불러오는 과정에서 해당 변수의 요인화과정이 생략되었을 것이다.
airquality {datasets}
R Documentation
New York Air Quality Measurements
Description
Daily air quality measurements in New York, May to September 1973.
Usage
airquality
Format
A data frame with 153 observations on 6 variables.
[,1]
Ozone
numeric
Ozone (ppb)
[,2]
Solar.R
numeric
Solar R (lang)
[,3]
Wind
numeric
Wind (mph)
[,4]
Temp
numeric
Temperature (degrees F)
[,5]
Month
numeric
Month (1--12)
[,6]
Day
numeric
Day of month (1--31)
Details
Daily readings of the following air quality values for May 1, 1973 (a Tuesday) to September 30, 1973.
Ozone: Mean ozone in parts per billion from 1300 to 1500 hours at Roosevelt Island
Solar.R: Solar radiation in Langleys in the frequency band 4000–7700 Angstroms from 0800 to 1200 hours at Central Park
Wind: Average wind speed in miles per hour at 0700 and 1000 hours at LaGuardia Airport
Temp: Maximum daily temperature in degrees Fahrenheit at La Guardia Airport.
Source
The data were obtained from the New York State Department of Conservation (ozone data) and the National Weather Service (meteorological data).
References
Chambers, J. M., Cleveland, W. S., Kleiner, B. and Tukey, P. A. (1983) Graphical Methods for Data Analysis. Belmont, CA: Wadsworth.
Examples
require(graphics)
pairs(airquality, panel = panel.smooth, main = "airquality data")
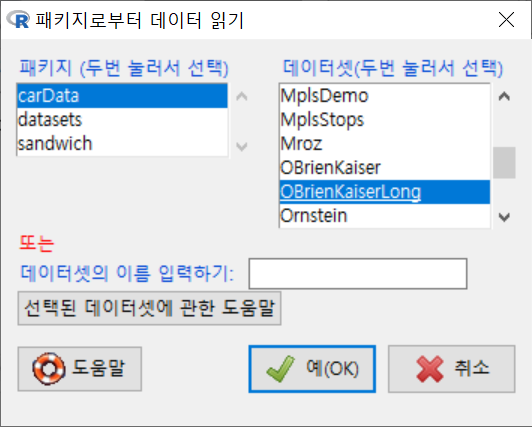
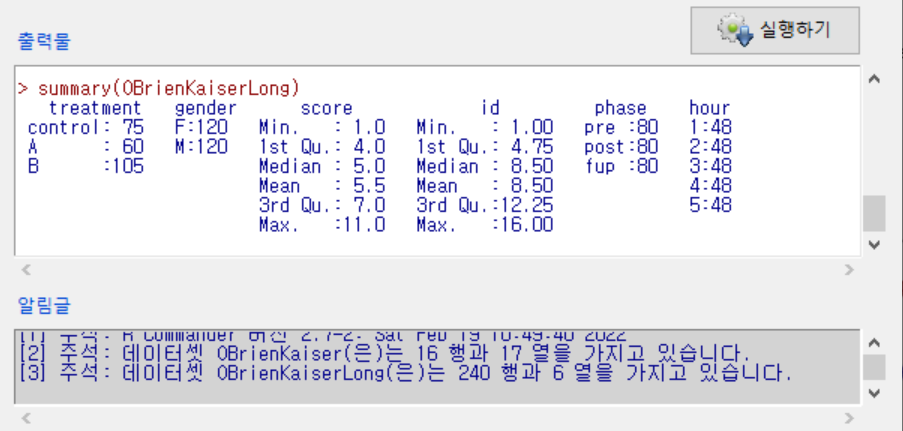
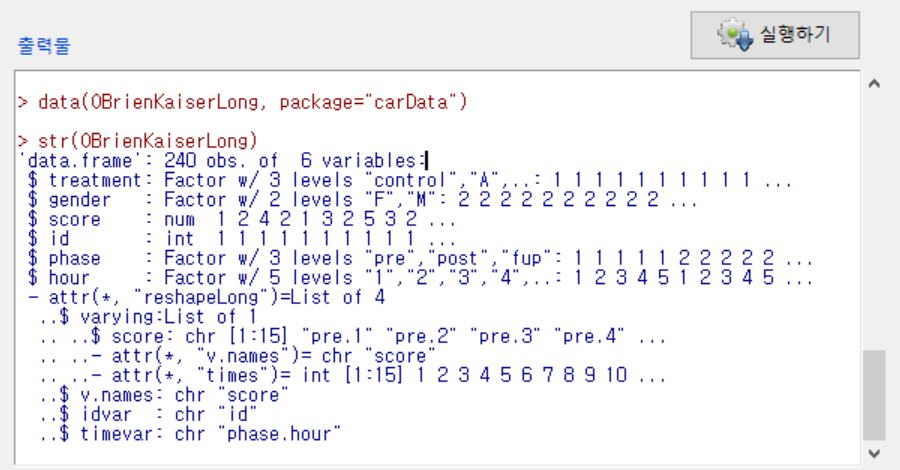
OBrienKaiserLong 데이터셋은 carData 패키지에 포함되어 있다. carData 패키지는 Rcmdr 패키지가 호출될 때 자동으로 함께 호출되기 때문에, OBrienKaiserLong 데이터셋을 R Commander에서 메뉴기능을 통해서 활성데이터셋으로 불러올 수 있다.
통계> 요약 > 활성 데이터셋 메뉴를 통하여 OBrienKaiserLong 데이터셋의 요약정보를 확인할 수 있다.
Windows 사례
summary() 함수를 이용한 것을 알 수 있다.
Windows 사례
str() 함수를 활용하여 입력창에 직접 str(OBrienKaiserLong)을 입력하고 실행하여, 출력창에 다음과 같이 OBrienKaiserLong 데이터셋의 구조적 정보도 확인할 수 있다.
Windows 사례
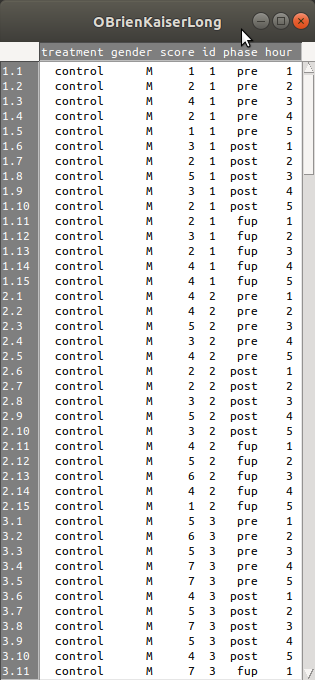
R Commander 화면에서 <데이터셋 보기> 버튼을 누르면 다음과 같은 내부 구성을 볼 수 있다:
Linux 사례 (Ubuntu 18.04)
OBrienKaiserLong {carData}
R Documentation
O'Brien and Kaiser's Repeated-Measures Data in "Long" Format
Description
Contrived repeated-measures data from O'Brien and Kaiser (1985). For details seeOBrienKaiser, which is for the "wide" form of the same data.
Usage
OBrienKaiserLong
Format
A data frame with 240 observations on the following 6 variables.
treatment
a between-subjects factor with levelscontrol,A,B.
gender
a between-subjects factor with levelsF,M.
score
the numeric response variable.
id
the subject id number.
phase
a within-subjects factor with levelspre,post,fup.
hour
a within-subjects factor with levels1,2,3,4,5.
Source
O'Brien, R. G., and Kaiser, M. K. (1985) MANOVA method for analyzing repeated measures designs: An extensive primer.Psychological Bulletin97, 316–333, Table 7.
OBrienKaiser 데이터셋은 R Commander에서 활성 데이터셋으로 이용할 수 있다. 그러나 '통계 > 요약 > 활성데이터셋' 기능은 사용할 수 없다. 다음과 같은 오류문을 Rgui 창에서 보게된다.
Error in sprintf(gettextRcmdr("There are %d variables in the data set %s.\nDo you want to proceed?"), : '%d'는 유효하지 않은 포맷입니다; 문자형 객체들에는 포맷 %s를 사용해주세요
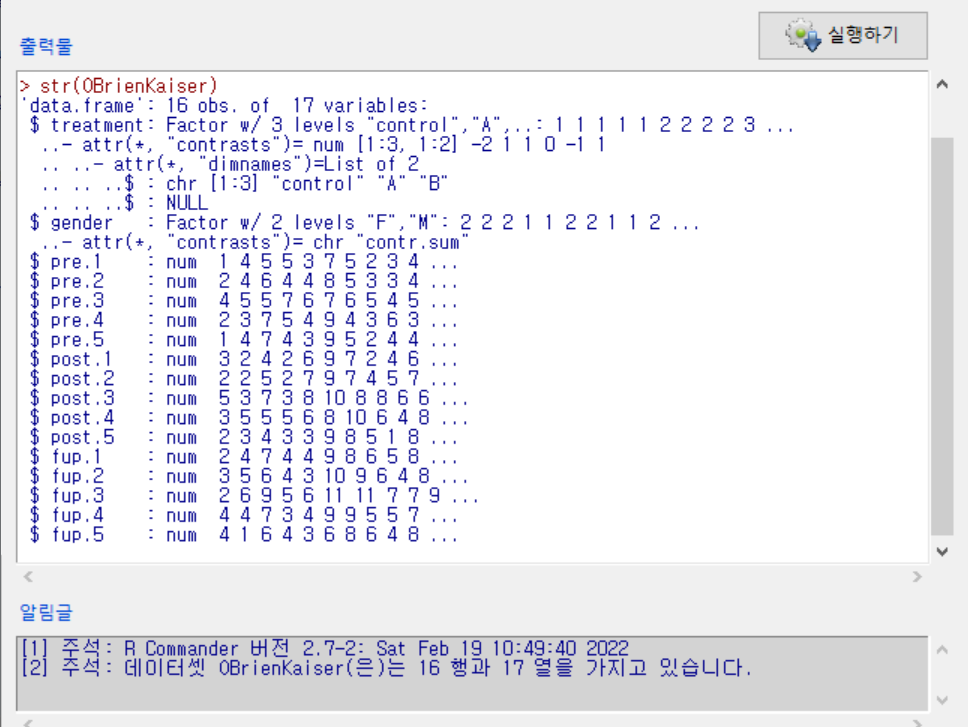
입력창에 str(OBrienKaiser) 함수를 입력하고 실행하여 OBrienKaiser 데이터셋의 구조를 살펴보자.
Windows 사례
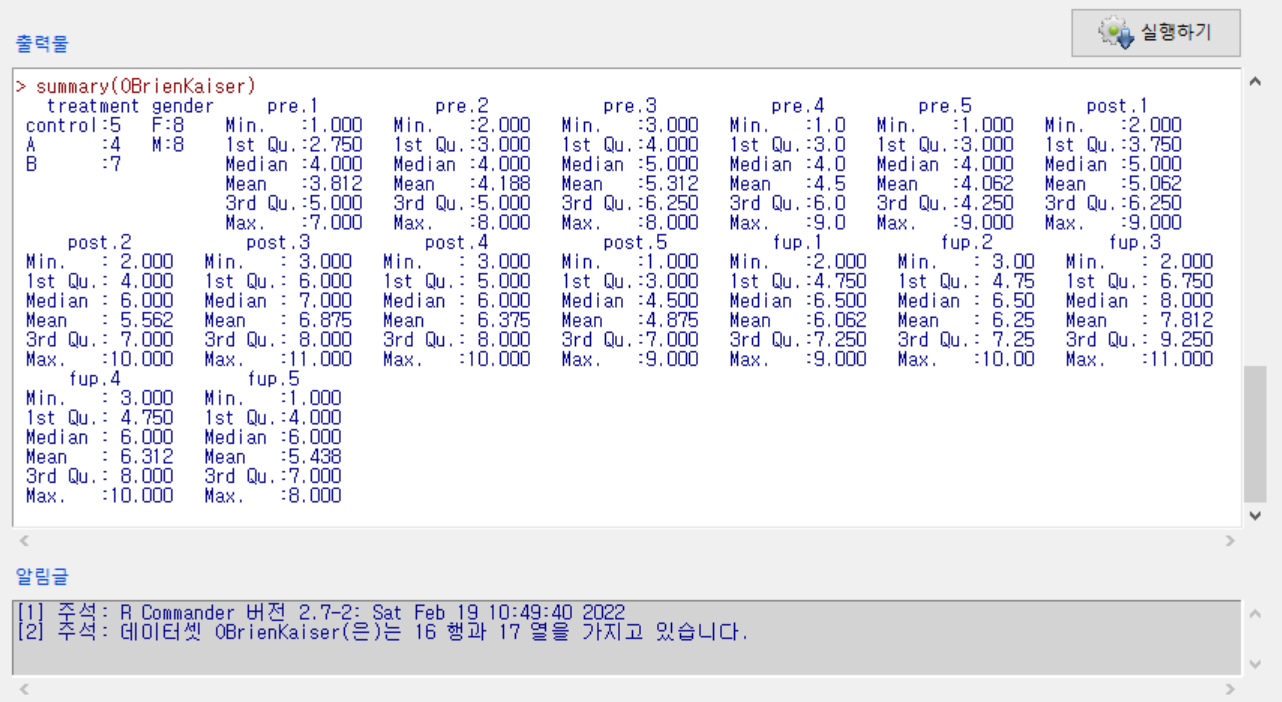
입력창에 summary(OBrienKaiser) 함수를 입력하고 실행하여 요약 정보를 살펴보자.
Windows 사례
OBrienKaiser {carData}
R Documentation
O'Brien and Kaiser's Repeated-Measures Data
Description
These contrived repeated-measures data are taken from O'Brien and Kaiser (1985). The data are from an imaginary study in which 16 female and male subjects, who are divided into three treatments, are measured at a pretest, postest, and a follow-up session; during each session, they are measured at five occasions at intervals of one hour. The design, therefore, has two between-subject and two within-subject factors.
The contrasts for the treatment factor are set to -2, 1, 1 and 0, -1, 1. The contrasts for the gender factor are set to contr.sum.
Usage
OBrienKaiser
Format
A data frame with 16 observations on the following 17 variables.
treatment
a factor with levels control A B
gender
a factor with levels F M
pre.1
pretest, hour 1
pre.2
pretest, hour 2
pre.3
pretest, hour 3
pre.4
pretest, hour 4
pre.5
pretest, hour 5
post.1
posttest, hour 1
post.2
posttest, hour 2
post.3
posttest, hour 3
post.4
posttest, hour 4
post.5
posttest, hour 5
fup.1
follow-up, hour 1
fup.2
follow-up, hour 2
fup.3
follow-up, hour 3
fup.4
follow-up, hour 4
fup.5
follow-up, hour 5
Source
O'Brien, R. G., and Kaiser, M. K. (1985) MANOVA method for analyzing repeated measures designs: An extensive primer. Psychological Bulletin 97, 316–333, Table 7.
R Commander의 메뉴 기반 사용법의 큰 특징은 활성 데이터셋에 관한 것이 될 것이다. 입력 창에 명령문을 입력하는 일반적인 방법과 달리 메뉴 기반 R Commander는 활성화된 데이터셋 하나만을 다룬다. (물론 데이터셋 병합하기는 두개 이상의 데이터셋을 필요로 한다)
Linux 사례 (MX 21)
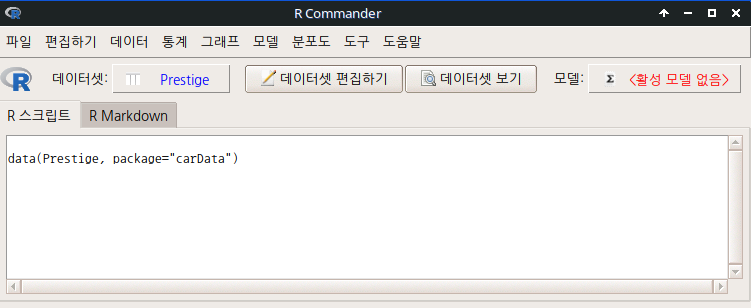
아래 화면에 왼쪽에 R 아이콘이 있고, 그 옆에 '데이터셋: Prestige'이 보일 것이다. Prestige 라는 데이터셋이 활성화되어서 R Commander에서 사용할 준비가 되었다는 의미가 된다:
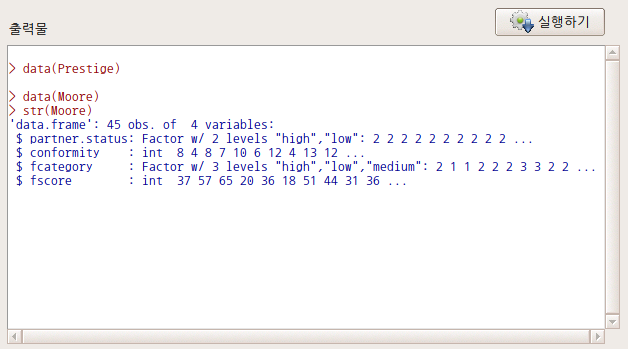
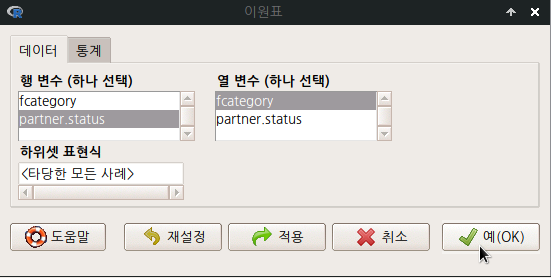
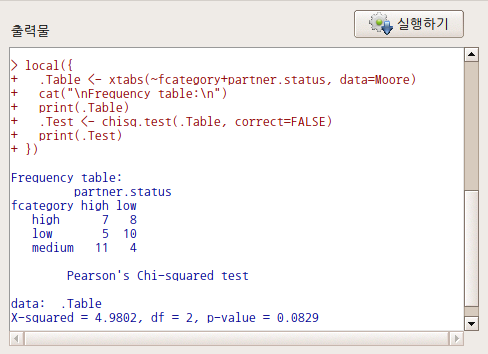
분석대상인 데이터셋에 요인형 변수가 한개 있거나, 하나도 없는 경우 분할표 메뉴의 오른쪽에 있는 <이원표>, <다원표> 기능은 불활성 음영 표시로 나타난다. 두개 이상의 요인형 변수가 있는 경우, 예를 들어 car 패키지에 포함된 Moore 데이터셋이 활성 데이터셋이 되는 경우 불활성 음영 표시가 사라진다.
Linux 사례 (MX21)
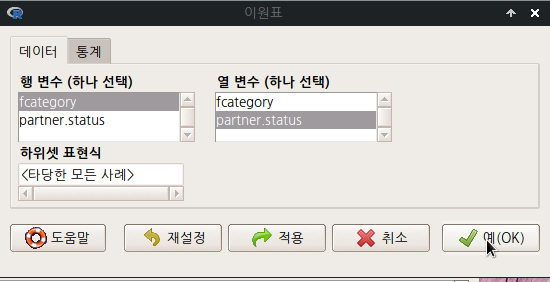
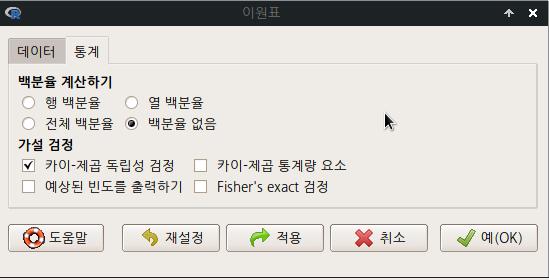
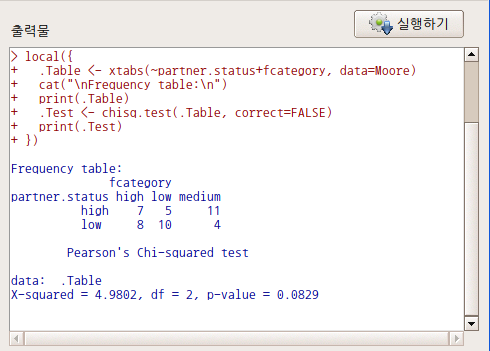
요인형 변수가 세개 이상 있는 경우, <다원표> 까지 활성화된다. 아래의 화면을 보면, partner.status, fcatetory 두개의 변수가 요인(factor)형이다. <이원표>는 활성화된 반면에, <다원표> 기능이 아직 활성화되지 않았다면, 요인형 변수가 두개 뿐인 데이터셋임을 간접적으로 알려준다.