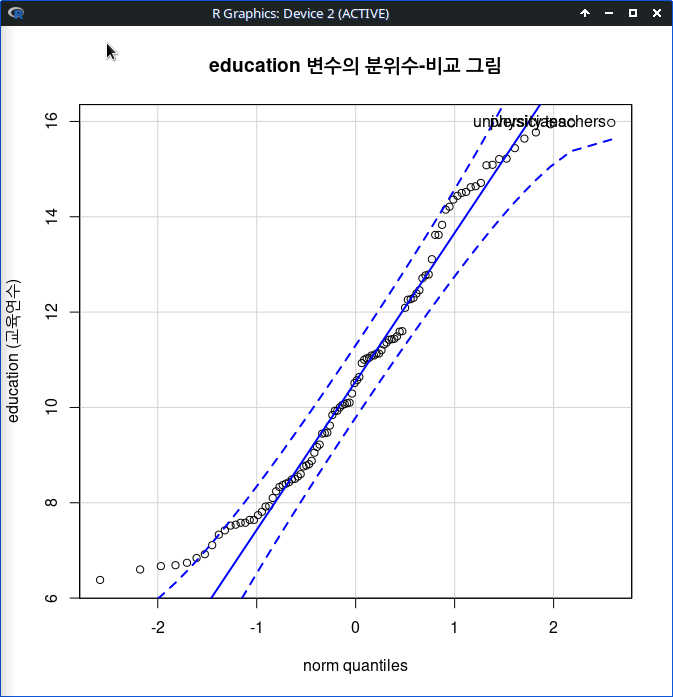
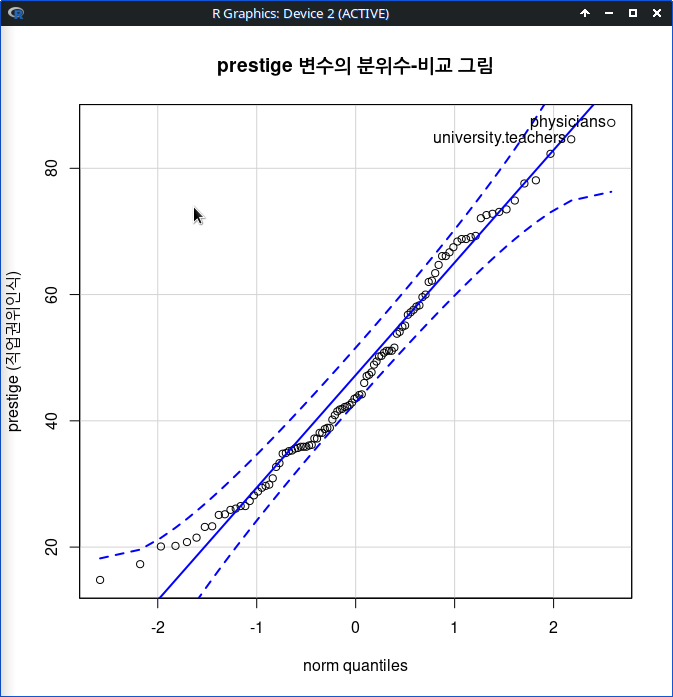
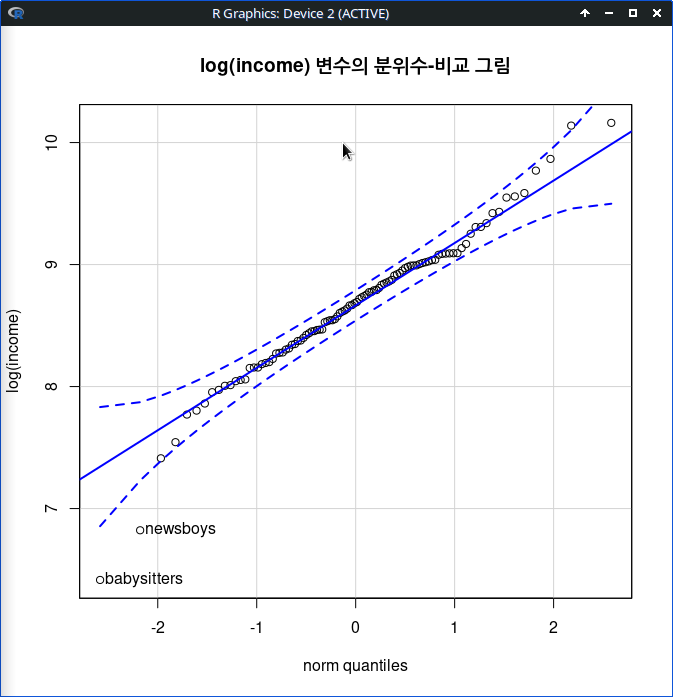
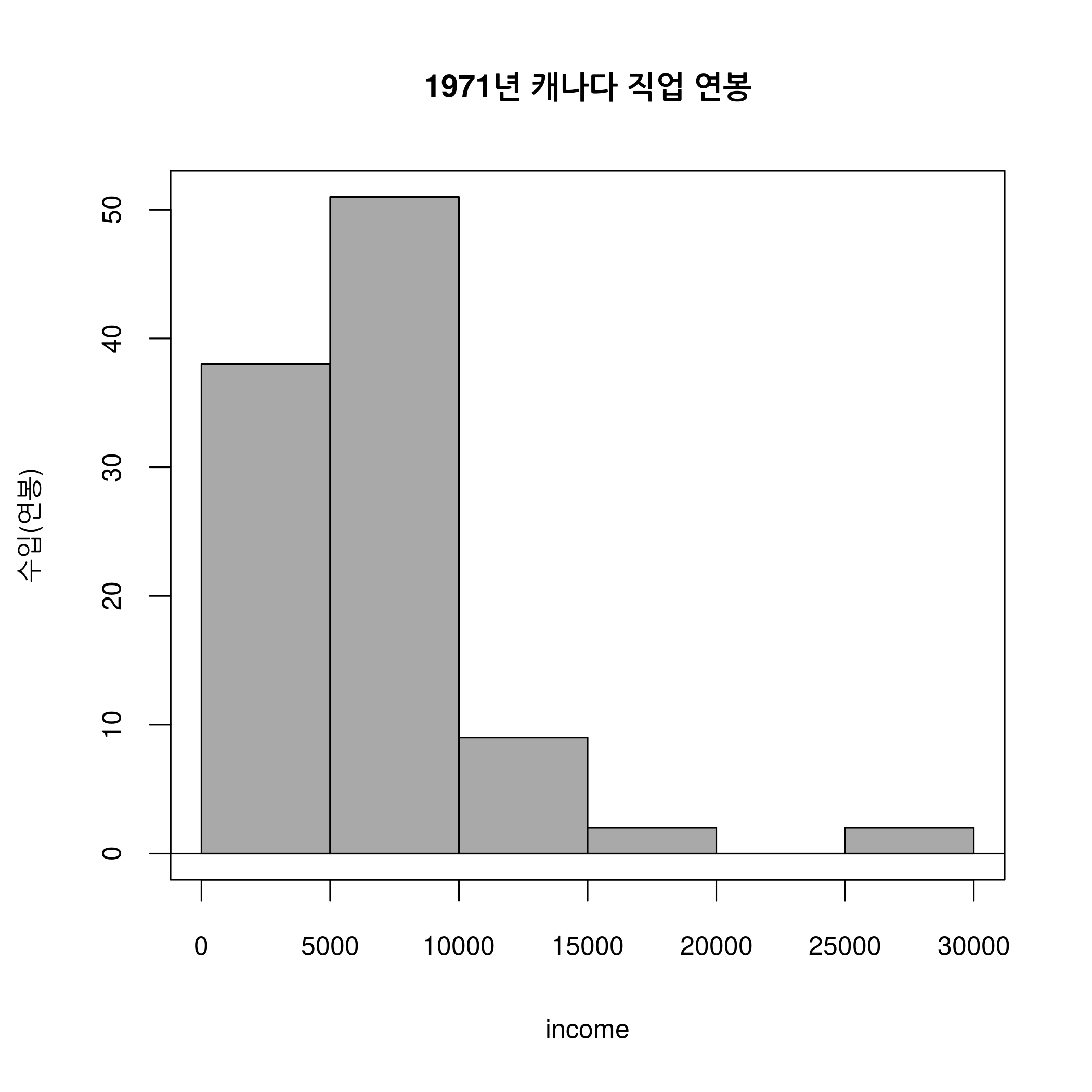
그래프 > 산점도...
Graphs > Scatterplot...
산점도(Scatterplot)은 두개의 수치형 변수 사이의 수리적 연관성에 관한 시각화 기법이다. 아래의 화면에서 각 하나씩을 x-변수와 y-변수에 선택해야 한다. Prestige 데이터셋에 있는 education (교육연수), income (수입, 연소득)을 각각 선택해보자.
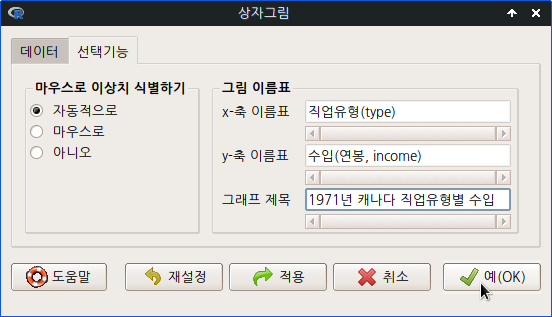
<선택기능>창에 여러가지 추가 기능과 선택사양들이 있다. 먼저 <그림 선택기능> 중에 <최소-제곱 선>, <평활선>을 선택해보자. 그리고 <그림 이름표와 점 정보>에 변수와 그래프를 이해하는 데 도움을 주는 내용을 입력한다. 그리고 <Point(점) 크기>, <축 텍스트 크기>, <축-이름표 텍스트 크기> 등의 크기를 조금씩 변경할 수 있다.
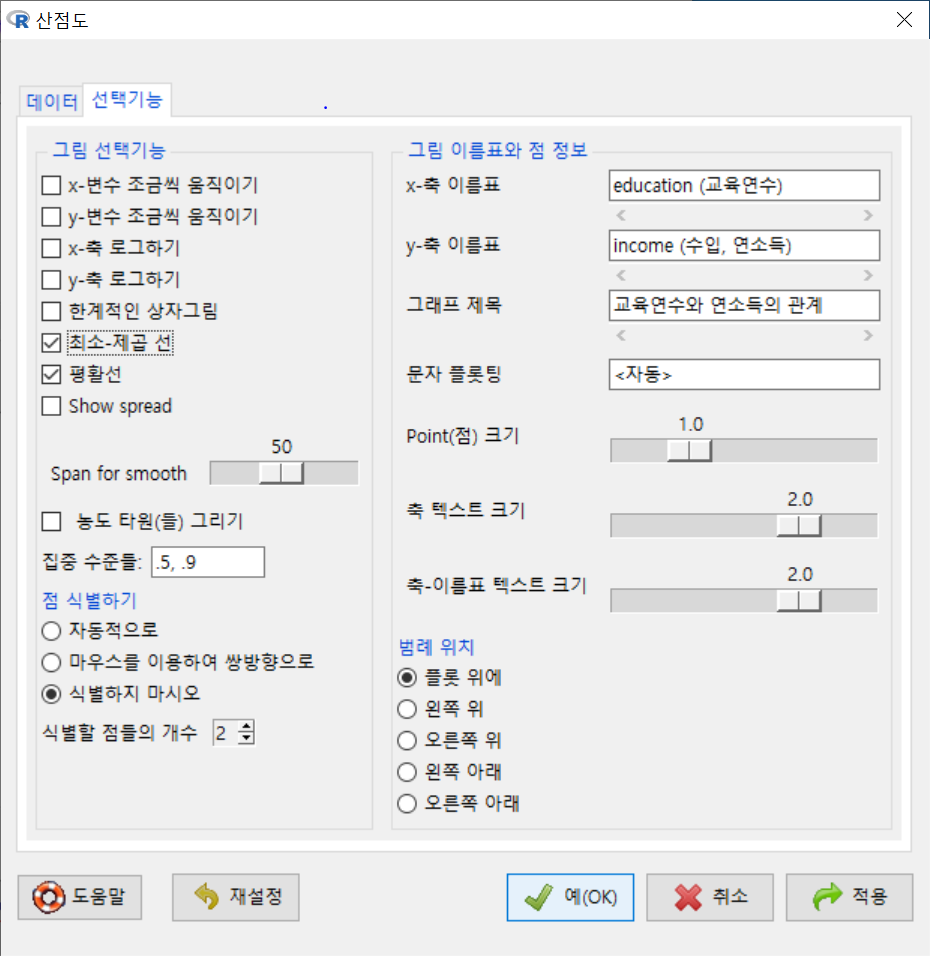
scatterplot(income~education, regLine=TRUE, smooth=list(span=0.5,
spread=FALSE), boxplots=FALSE, xlab="education (교육연수)",
ylab="income (수입, 연소득)", main="교육연수와 연소득의 관계", cex.axis=1.5, cex.lab=1.5,
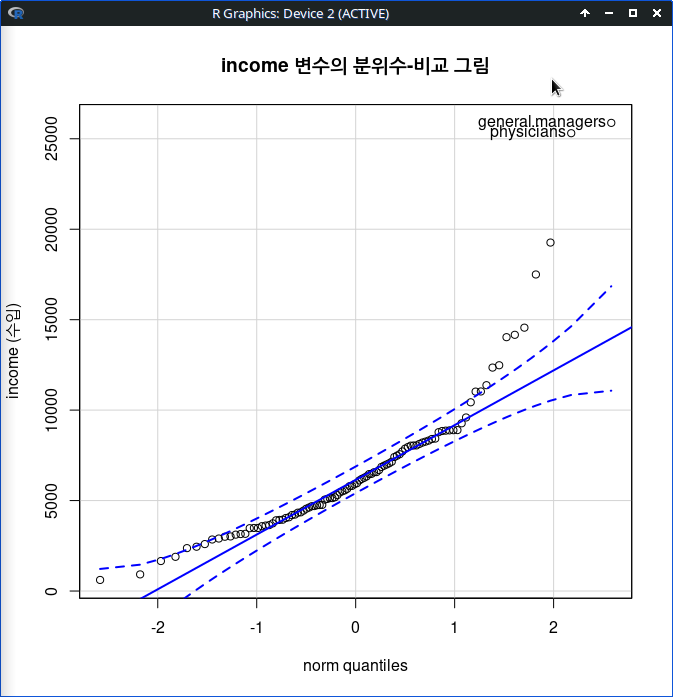
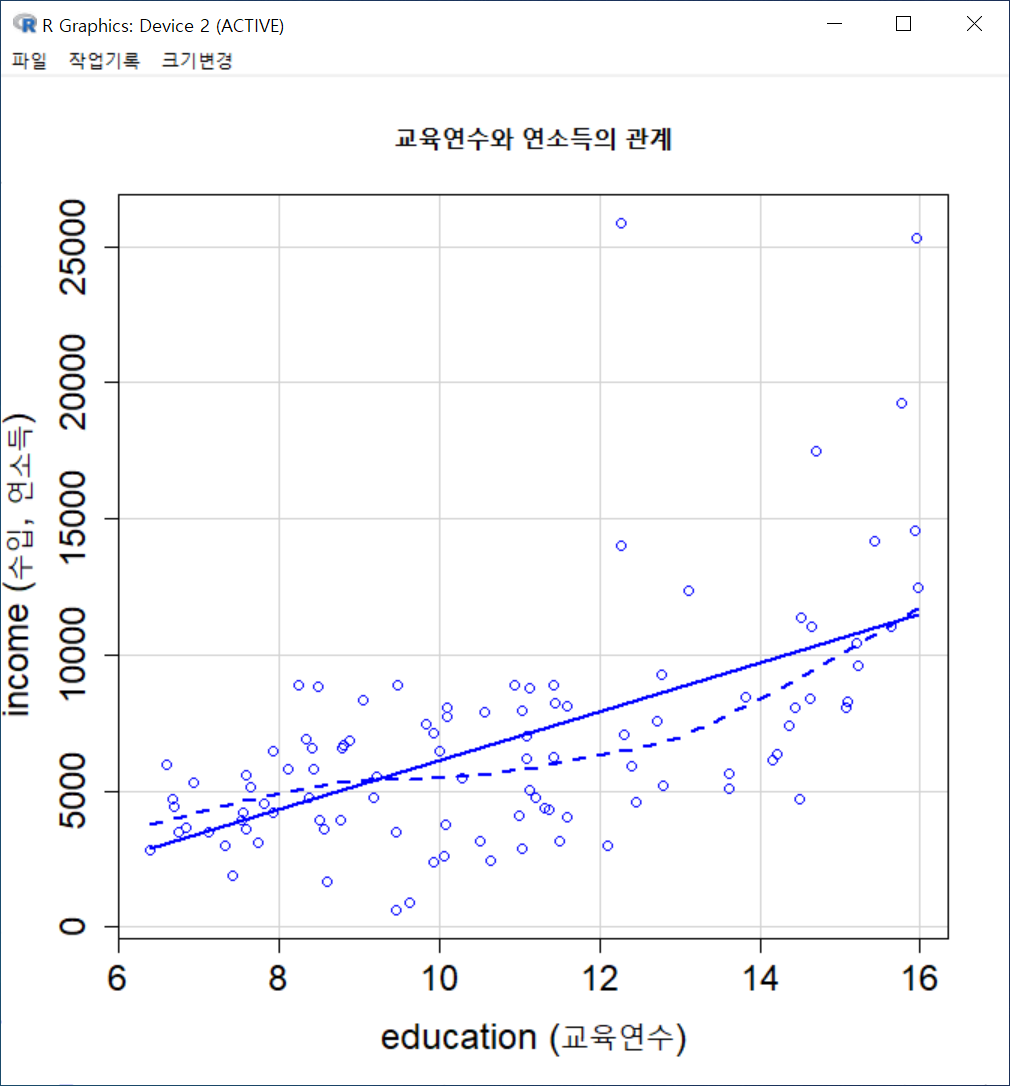
data=Prestige)새로운 그래픽장치 창에 산점도가 출력된다. <교육연수와 연소득의 관계>를 시각적으로 살펴보고자 한 목적으로 점들의 분포와 추가된 최소제곱선, 평활선 등을 점검한다. 교육연수와 연소득의 관계의 방향, 크기 및 경향성 등에 대한 통찰력을 키울 수 있다.
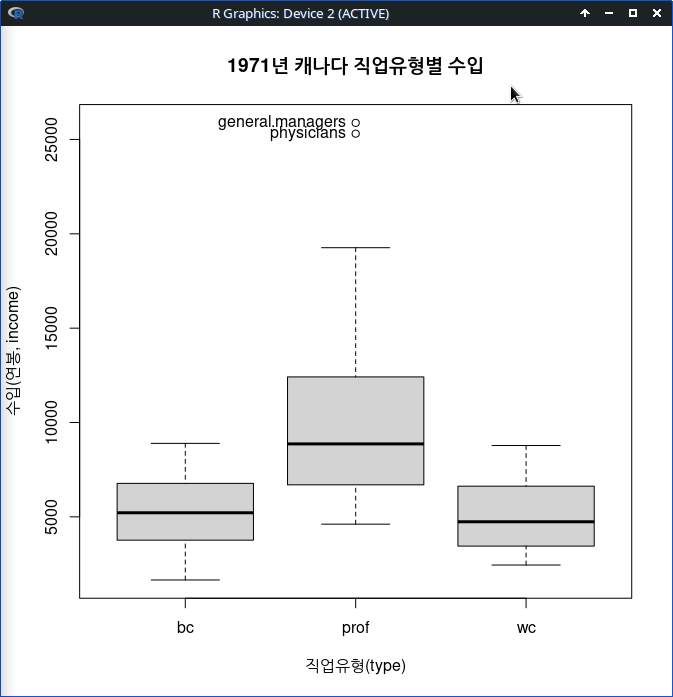
한편, 산점도에 요인형 변수의 수준별로 나누어 시각화를 할 수 있다. Prestige 데이터셋에는 type 이라는 요인형 변수가 있는데, 직업유형에 따른 <교육연수와 연소득의 관계>를 보다 미시적으로 살펴볼 수 있다. 그리고 x-축, y-축 이름 옆에 <한계적인 상자그림>을 추가하여 각 변수들의 수치적 특징을 추가할 수 있다.
scatterplot(income~education | type, regLine=TRUE, smooth=list(span=0.5,
spread=FALSE), boxplots='xy', xlab="education (교육연수)", ylab="income (수입,
연소득)", main="교육연수와 연소득의 관계", cex.axis=1.5, cex.lab=1.5, by.groups=TRUE,
data=Prestige)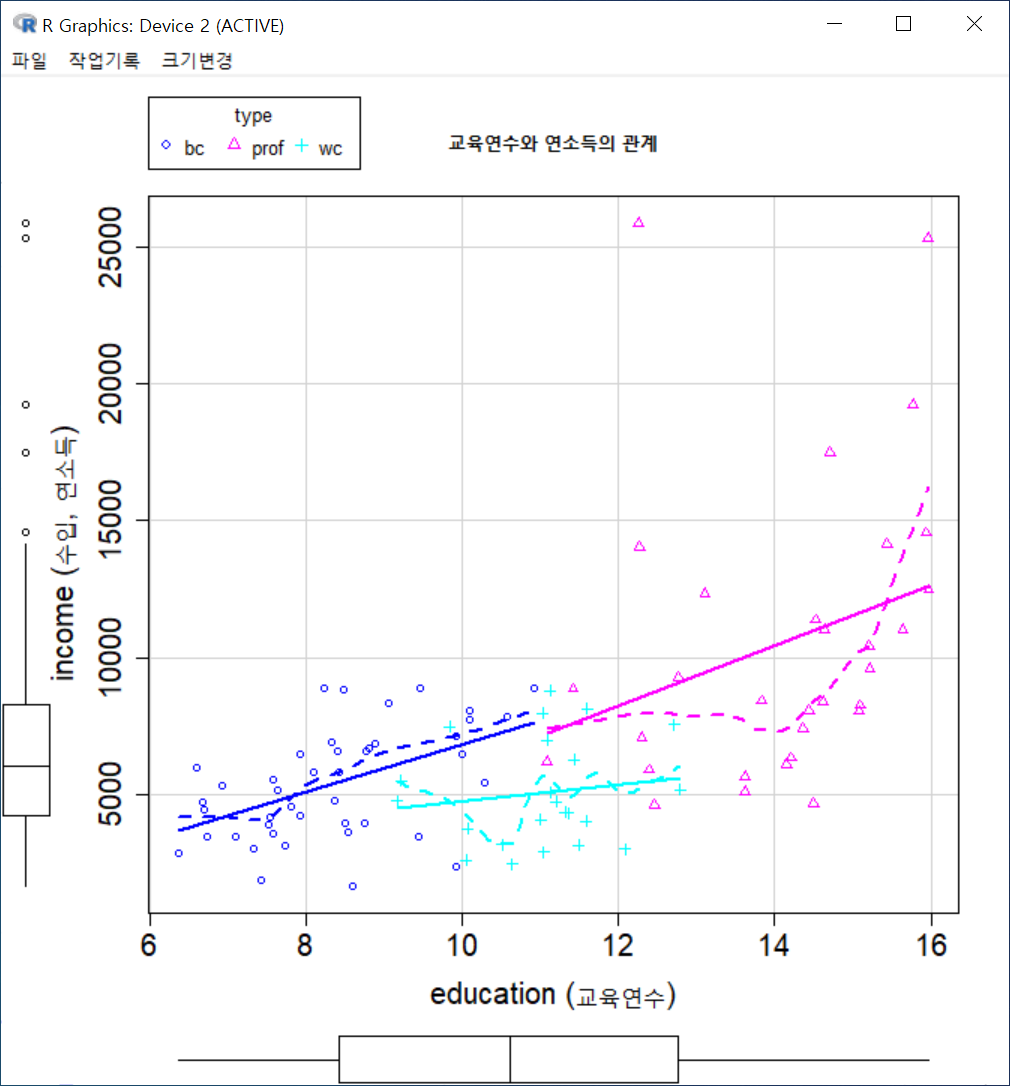
?scatterplot # car 패키지의 scatterplot 도움말 보기
scatterplot(prestige ~ income, data=Prestige, ellipse=TRUE)
scatterplot(prestige ~ income, data=Prestige, smooth=list(smoother=quantregLine))
# use quantile regression for median and quartile fits
scatterplot(prestige ~ income | type, data=Prestige,
smooth=list(smoother=quantregLine, var=TRUE, span=1, lwd=4, lwd.var=2))
scatterplot(prestige ~ income | type, data=Prestige, legend=list(coords="topleft"))
scatterplot(vocabulary ~ education, jitter=list(x=1, y=1),
data=Vocab, smooth=FALSE, lwd=3)
scatterplot(infantMortality ~ ppgdp, log="xy", data=UN, id=list(n=5))
scatterplot(income ~ type, data=Prestige)
## Not run:
# remember to exit from point-identification mode
scatterplot(infantMortality ~ ppgdp, id=list(method="identify"), data=UN)
## End(Not run)