데이터 > 활성 데이터셋 > 활성 데이터셋 정렬하기...
Data > Active Data set > Sort active data set...
데이터셋의 행의 순서를 조정할 수 있다. 이 기능은 특정 변수(들)을 선택하여 증가/감소 등의 순서로 행의 순서를 조정하는 기능이다. 보통 데이터셋에서 필요 변수(사례들)를 선택하여 하위셋을 만들고, 이후 내용적인 이해를 위하여 이 기능을 사용한다.
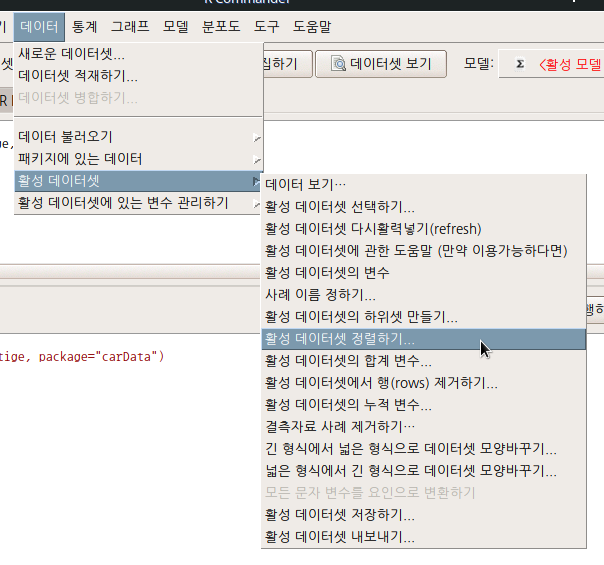
새롭게 정렬할 변수(들)을 선택하고, 증가/감소 등의 방향을 결정한 후, 새로운 데이터셋의 이름을 입력하게 된다. 입력하지 않으면 현재 사용중인 데이터셋의 이름을 덮어쓰는 위험이 있다. 경험적으로 나의 경우는 데이터셋.sort1, 데이터셋.sort2 등으로 새로운 데이터셋의 이름을 정한다.
직종의 권위에 대한 인식의 높낮이를 기준으로 자료를 정렬해보자. prestige 변수를 선택하고, <방향 정렬하기>에서 감소하기를 선택하고, <새로운 데이터셋 이름>에서 Prestige.sort1 이라고 입력한다.
출력창에 함수의 용례를 확인할 수 있다. 정렬의 기준 변수를 선택하고, order() 함수와 높은 순서로 정렬하는 인자인 'decreasing=TRUE'를 사용한다. 새로운데이터셋 <- with(활성데이터셋, 활성데이터셋[order(기준변수이름, decreasing=TRUE), ]) 등의 함수 용례를 보게된다:

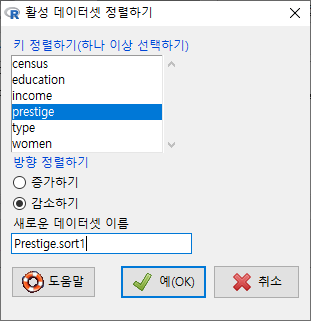
R Commander의 상단에 있는 R 아이콘 옆에 <데이터셋: Prestige.sort1>이라고 활성데이텃 이름이 바뀐 것을 보게될 것이다. 어떻게 데이터셋이 정렬되었는지 보려면 <데이터셋 보기> 버튼을 누른다.
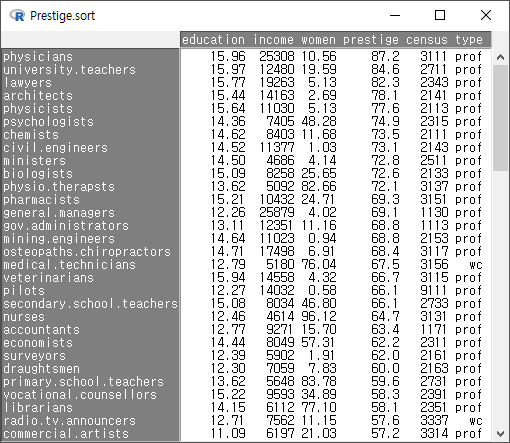
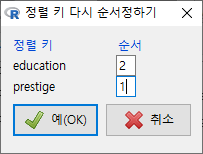
두개 이상의 변수를 선택할 경우는 추가 대화창에서 정렬 키의 순서를 결정할 수 있다. 직업의 권위가 높은 순서로, 교육 연수가 높은 순서로 정렬해보자.
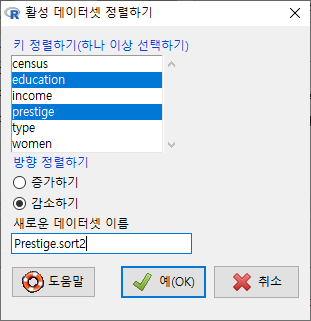
기준(key)이 되는 변수가 하나일 때와 달리, 둘 이상의 변수를 선택할 때는 <정렬 키 다시 순서정하기> 창이 등장한다. 앞서 만든 기준을 위하여 prestige를 1로, education을 2로 순서를 바꿔보자.
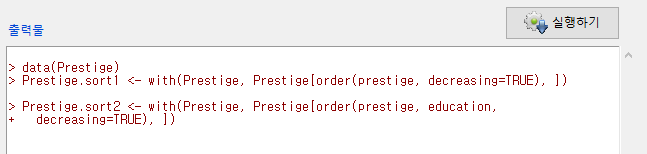
R Commander의 화면에서 활성 데이터셋이 Prestige.sort2로 바뀐다. 그리고 출력창에 새로운 함수 용례가 다음과 같이 등장할 것이다. 새로운데이터셋 <- with(활성데이터셋, 활성데이터셋[order(기준변수1이름, 기준변수2이름, decreasing=TRUE), ])
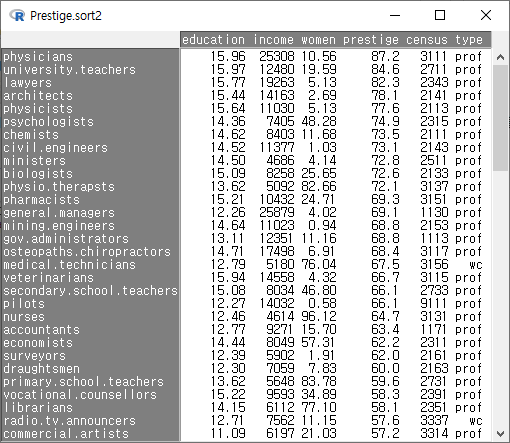
<데이터셋 보기>를 눌러서 정렬의 결과를 살펴보자. prestige 변수의 사례 값이 68.8인 것이 두개 있다. mining.engineers, gov.administrators 인데, 둘째 기준변수인 education의 높은 순서로 정렬되어 있다. 각각 14.64, 13.11 이다. 앞서 기준변수가 prestige 하나였던 데이터셋과 정렬을 비교해보자. 상단의 Prestige.sort1 데이터셋에는 gov.administrators가 mining.engineers보다 위에 있는 것을 확인할 수 있다.
?order # base 패키지에 있는 order 도움말 보기
require(stats)
(ii <- order(x <- c(1,1,3:1,1:4,3), y <- c(9,9:1), z <- c(2,1:9)))
## 6 5 2 1 7 4 10 8 3 9
rbind(x, y, z)[,ii] # shows the reordering (ties via 2nd & 3rd arg)
## Suppose we wanted descending order on y.
## A simple solution for numeric 'y' is
rbind(x, y, z)[, order(x, -y, z)]
## More generally we can make use of xtfrm
cy <- as.character(y)
rbind(x, y, z)[, order(x, -xtfrm(cy), z)]
## The radix sort supports multiple 'decreasing' values:
rbind(x, y, z)[, order(x, cy, z, decreasing = c(FALSE, TRUE, FALSE),
method="radix")]
## Sorting data frames:
dd <- transform(data.frame(x, y, z),
z = factor(z, labels = LETTERS[9:1]))
## Either as above {for factor 'z' : using internal coding}:
dd[ order(x, -y, z), ]
## or along 1st column, ties along 2nd, ... *arbitrary* no.{columns}:
dd[ do.call(order, dd), ]
set.seed(1) # reproducible example:
d4 <- data.frame(x = round( rnorm(100)), y = round(10*runif(100)),
z = round( 8*rnorm(100)), u = round(50*runif(100)))
(d4s <- d4[ do.call(order, d4), ])
(i <- which(diff(d4s[, 3]) == 0))
# in 2 places, needed 3 cols to break ties:
d4s[ rbind(i, i+1), ]
## rearrange matched vectors so that the first is in ascending order
x <- c(5:1, 6:8, 12:9)
y <- (x - 5)^2
o <- order(x)
rbind(x[o], y[o])
## tests of na.last
a <- c(4, 3, 2, NA, 1)
b <- c(4, NA, 2, 7, 1)
z <- cbind(a, b)
(o <- order(a, b)); z[o, ]
(o <- order(a, b, na.last = FALSE)); z[o, ]
(o <- order(a, b, na.last = NA)); z[o, ]
## speed examples on an average laptop for long vectors:
## factor/small-valued integers:
x <- factor(sample(letters, 1e7, replace = TRUE))
system.time(o <- sort.list(x, method = "quick", na.last = NA)) # 0.1 sec
stopifnot(!is.unsorted(x[o]))
system.time(o <- sort.list(x, method = "radix")) # 0.05 sec, 2X faster
stopifnot(!is.unsorted(x[o]))
## large-valued integers:
xx <- sample(1:200000, 1e7, replace = TRUE)
system.time(o <- sort.list(xx, method = "quick", na.last = NA)) # 0.3 sec
system.time(o <- sort.list(xx, method = "radix")) # 0.2 sec
## character vectors:
xx <- sample(state.name, 1e6, replace = TRUE)
system.time(o <- sort.list(xx, method = "shell")) # 2 sec
system.time(o <- sort.list(xx, method = "radix")) # 0.007 sec, 300X faster
## double vectors:
xx <- rnorm(1e6)
system.time(o <- sort.list(xx, method = "shell")) # 0.4 sec
system.time(o <- sort.list(xx, method = "quick", na.last = NA)) # 0.1 sec
system.time(o <- sort.list(xx, method = "radix")) # 0.05 sec, 2X faster'Data > Active data set' 카테고리의 다른 글
| 10. Remove row(s) from active data set... (0) | 2019.09.08 |
|---|---|
| 9. Aggregate variables in active data set... (0) | 2019.09.08 |
| 7. Subset active data set... (0) | 2019.09.08 |
| 6. Set case names... (0) | 2019.09.08 |
| 5. Variables in active data set (0) | 2019.09.08 |