데이터 > 활성 데이터셋 > 활성 데이터셋의 하위셋 만들기...
Data > Active Data set > Subset active data set...
데이터셋에 담긴 모든 변수를 분석에 활용하는 경우는 거의 없다. 분석을 위하여 데이터셋의 일부를 사용하는 경우가 일반적이다. 분석에 필요한 변수집단을 선택하여 하위셋을 만드는 기능이다.

변수집단을 선택할 경우는 <모든 변수 사용하기>에 기본지정된 옵션을 해제해야 한다. 물론 변수일부를 선택하는 것과 별개로 사례값(행) 일부를 선택할 수도 있다. 이 경우는 사용자가 직접 <하위셋 표현식>에 스크립트를 입력해야 한다. 초보자는 당황할 수 있다.

변수 일부나 행 일부를 선택한 후에는 새로운 데이터셋 이름을 입력해야 한다. 그렇지 않으면 기존 데이터셋 이름을 덮어쓰는 위험이 발생한다. 경험적으로 나는 하위데이터셋 이름은 데이터셋.sub1, 데이터셋.sub2 또는 sub1.데이터셋, sub2.데이터셋 등으로 사용하여 원데이터의 이름을 유지시킨다.
Prestige 데이터셋에서 변수 네개를 선택한다고 하자. education, income, prestige, type 변수를 선택하고, sub1.Prestige라고 데이터셋의 이름을 붙였다고 하자.
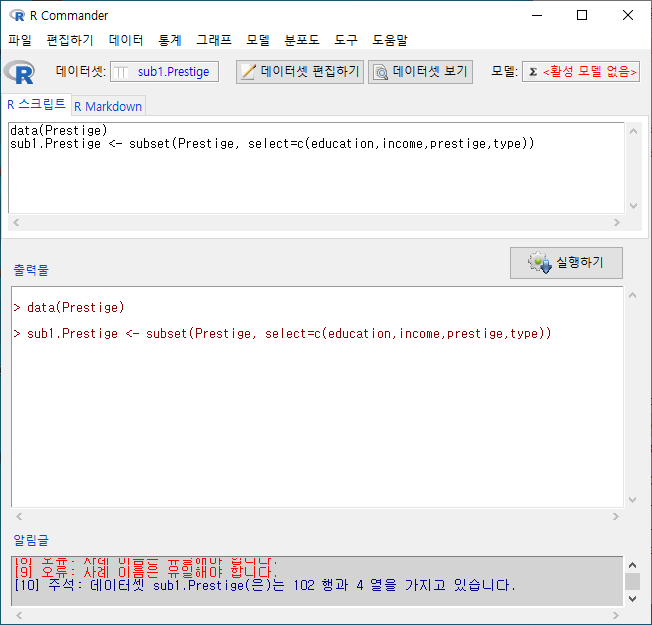
그런데, type 변수에는 "prof", "bc", "wc"라는 요인(factor)형 정보가 담겨있다. 이 중에서 전문직(prof)에 관한 데이터의 정보만 추출하려면 다음과 같이 조건을 지정해야 한다.
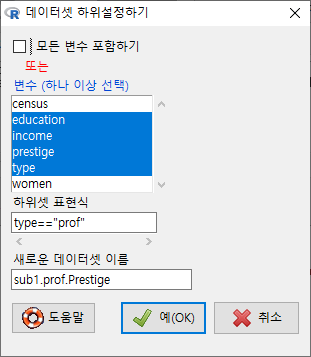
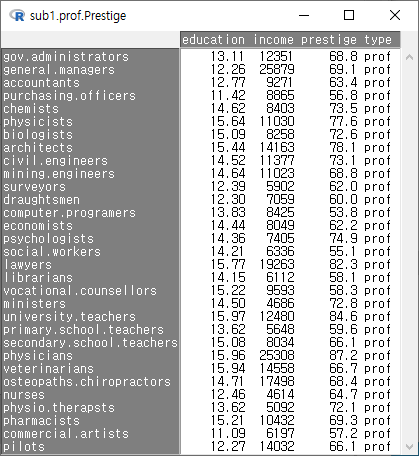
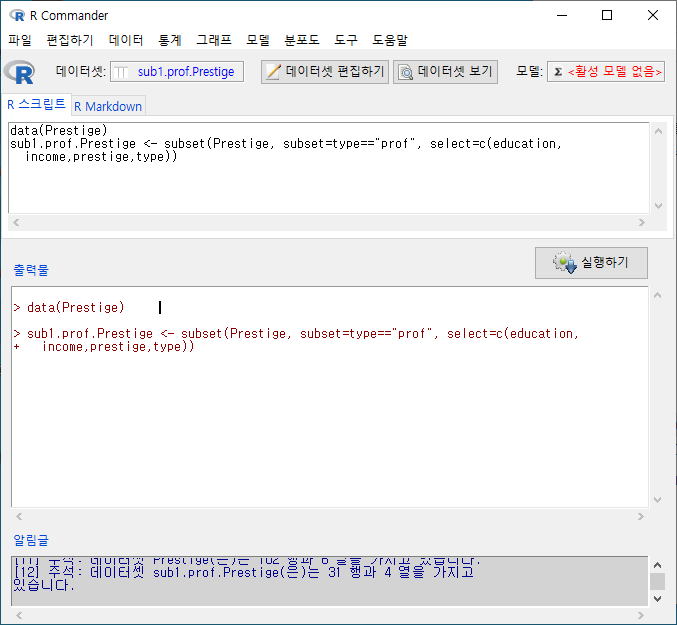
다음 화면의 입력창, 출력창, 알림글을 살펴보라. 활성 데이터셋의 이름이 sub1.prof.Prestige라고 바뀌었고, subset()의 인자가 추가되었으며, sub1.prof.Prestige 데이터셋의 행과 열 정보를 찾을 수 있다:
subset(데이터셋이름, subset=조건, select=선택된변수목록)
?subset # base 패키지의 subset 도움말 보기
subset(airquality, Temp > 80, select = c(Ozone, Temp))
subset(airquality, Day == 1, select = -Temp)
subset(airquality, select = Ozone:Wind)
with(airquality, subset(Ozone, Temp > 80))
## sometimes requiring a logical 'subset' argument is a nuisance
nm <- rownames(state.x77)
start_with_M <- nm %in% grep("^M", nm, value = TRUE)
subset(state.x77, start_with_M, Illiteracy:Murder)
# but in recent versions of R this can simply be
subset(state.x77, grepl("^M", nm), Illiteracy:Murder)'Data > Active data set' 카테고리의 다른 글
| 9. Aggregate variables in active data set... (0) | 2019.09.08 |
|---|---|
| 8. Sort active data set... (6) | 2019.09.08 |
| 6. Set case names... (0) | 2019.09.08 |
| 5. Variables in active data set (0) | 2019.09.08 |
| 4. Help on active data set (if available) (0) | 2019.09.08 |