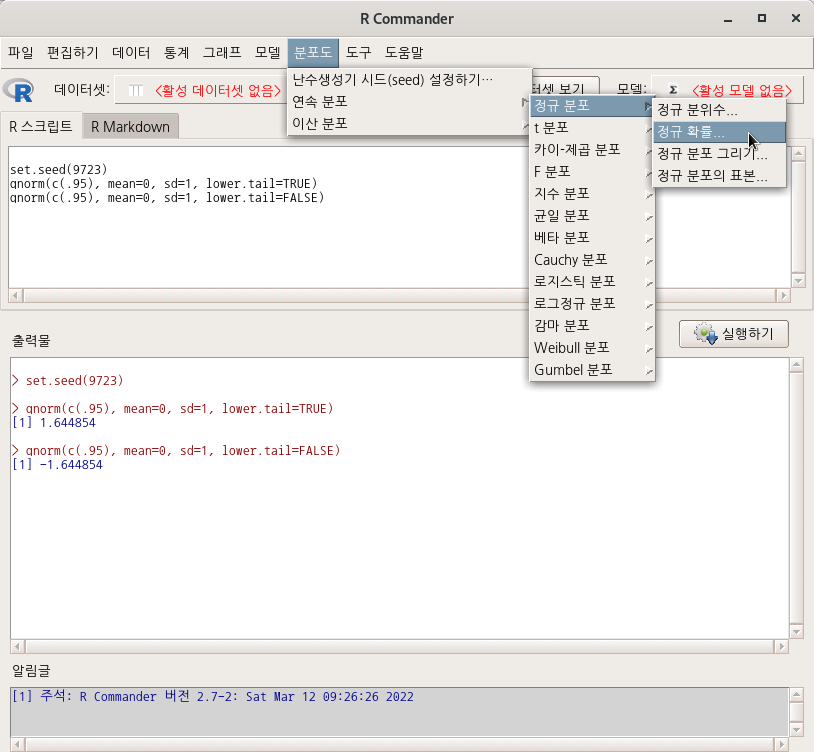
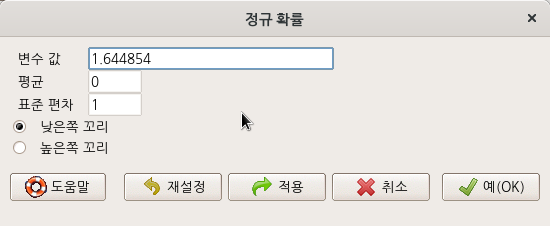
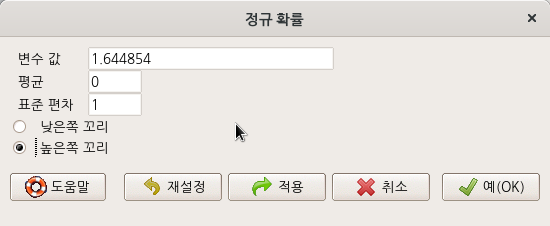
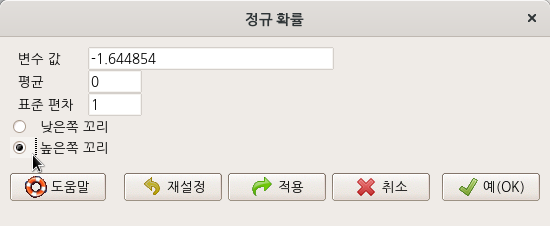
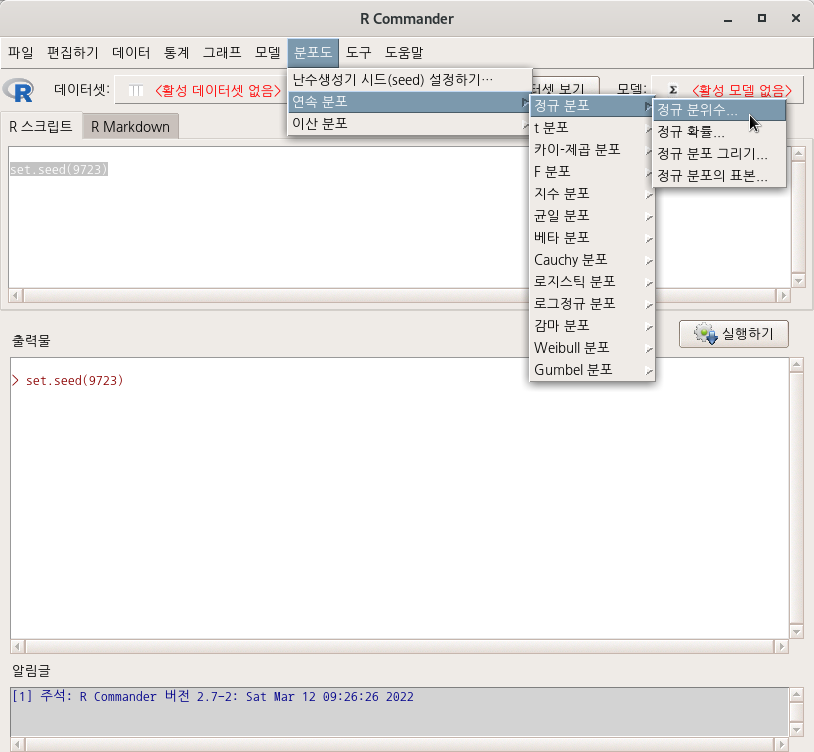
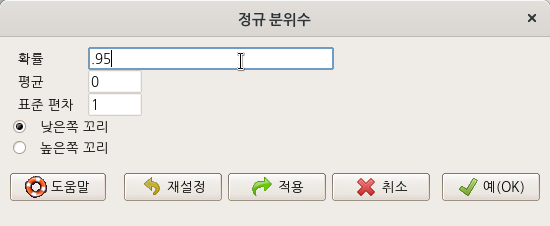
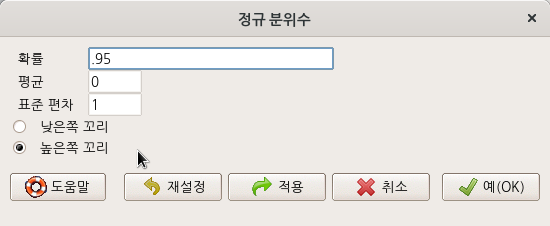
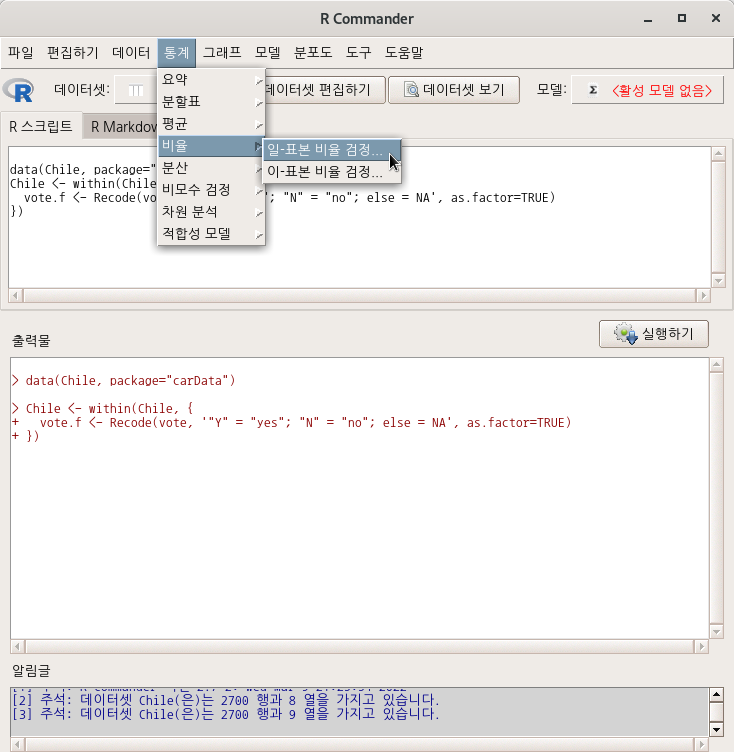
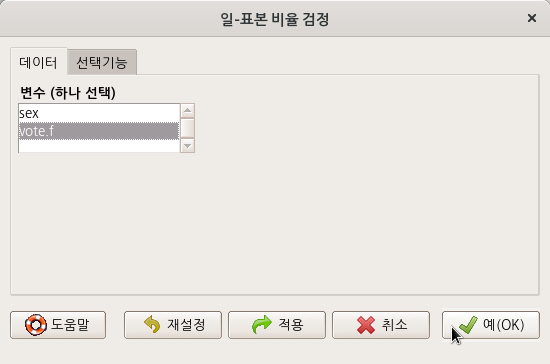
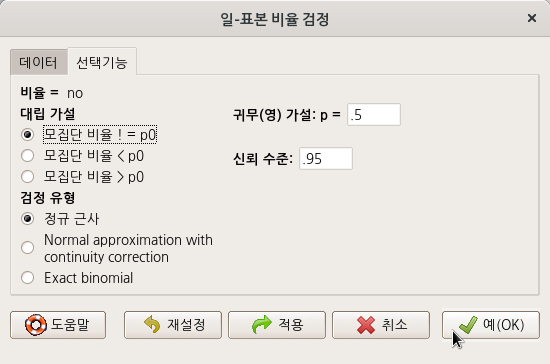
요인형 변수를 두개 이상 가지고 있는 데이터셋이 활성화되어 있다면, '통계 > 비율 > 이-표본 비율 검정..' 메뉴 기능을 이용할 수 있다. carData 패키지에 있는 Chile 데이터셋을 활용해서 연습해보자. 먼저, '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 통하여 Chile 데이터셋을 활성화시키자. R Commander 상단에 'Chile'라는 데이터셋이 활성화되었는지 확인하자.
local({
.Table <- xtabs(~ vote.f , data= Chile )
cat("\nFrequency counts (test is for first level):\n")
print(.Table)
prop.test(rbind(.Table), alternative='two.sided', p=.5, conf.level=.95, correct=FALSE)
})
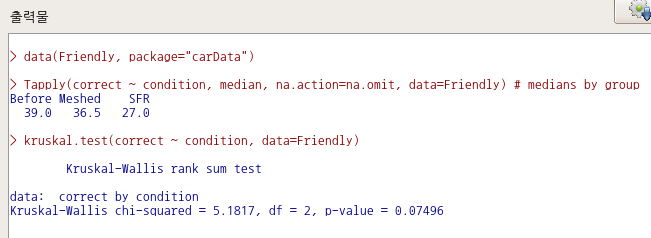
출력창에 나오는 결과는 아래와 같다:
Linux 사례 (MX 21)
?prop.test # stats 패키지의 prop.test 도움말 보기
heads <- rbinom(1, size = 100, prob = .5)
prop.test(heads, 100) # continuity correction TRUE by default
prop.test(heads, 100, correct = FALSE)
## Data from Fleiss (1981), p. 139.
## H0: The null hypothesis is that the four populations from which
## the patients were drawn have the same true proportion of smokers.
## A: The alternative is that this proportion is different in at
## least one of the populations.
smokers <- c( 83, 90, 129, 70 )
patients <- c( 86, 93, 136, 82 )
prop.test(smokers, patients)
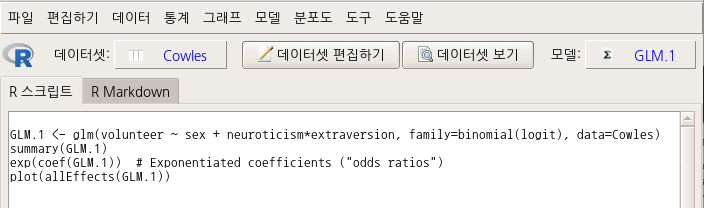
'모델 > 그래프 > 효과 그림...' 기능은 미리 모델이 만들어져야 이용할 수 있다. 만들어진 모델은 아래와 같이 R Commander 상단에서 확인할 수 있다. carData 패키지의 Cowles 데이터셋으로 만든 GLM.1 모델을 활용하는 것이다.
Linux 사례 (MX 21)
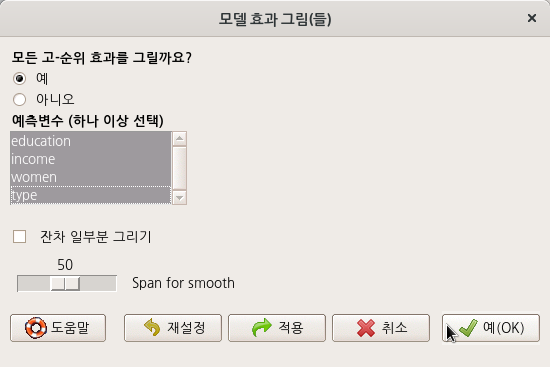
<모델 효과 그림(들)> 창 중간에 있는 <예측변수 (하나 이상 선택)> 기능에서 sex, neuroticism, extraversion 세 변수를 모두 선택해보자.
Linux 사례 (MX 21)
plot(allEffects(GLM.1))
Linux 사례 (MX 21)
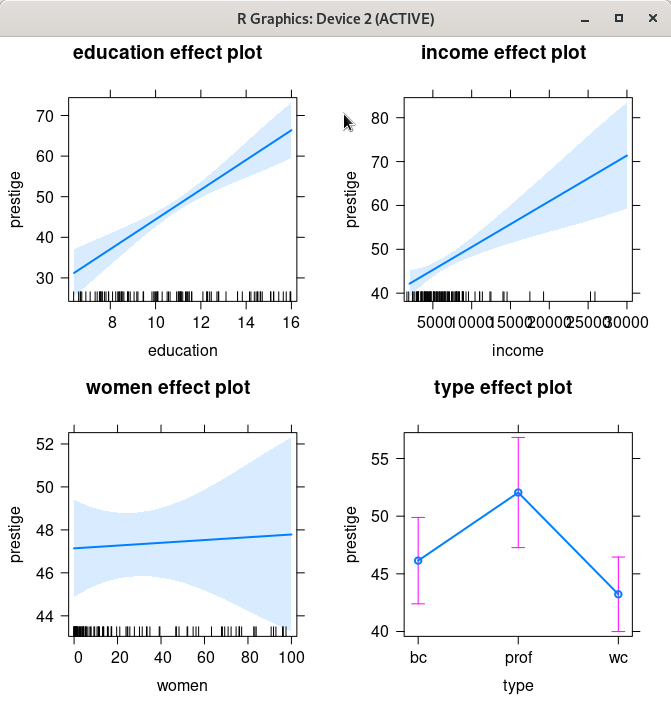
carData 패키지의 Prestige 데이터셋을 이용하여 연습해보자. 아래와 같이 prestige (직업의 사회적 권위)에 대한 education (교육연수), income (연수입), women (여성 참여율)의 영향력을 type (직업유형)별로 살펴보는 모델을 만들었다고 가정하자.
data(Prestige, package="carData")
LinearModel.1 <- lm(prestige ~ education + income + women + type, data=Prestige)
summary(LinearModel.1)
아래와 같이 LinearModel.1의 요약 정보가 출력될 것이다.
Linux 사례 (MX 21)
이러한 LinearModel.1의 효과 그림을 시각화 할 수 있다. <모델 효과 그림(들)> 창의 <예측변수(하나 이상 선택)> 기능에서 네개의 변수를 모두 선택해보자. 그리고 예(OK) 버튼을 누른다.
Linux 사례 (MX 21)
plot(allEffects(LinearModel.1))
아래와 같이 그래픽 장치 창에 선택된 변수 네개의 효과 그림이 등장할 것이다.
Linux 사례 (MX 21)
한편, <잔차 일부분 그리기> 기능을 선택해보자.
Linux 사례 (MX 21)
그래픽 장치 창에 잔차들이 플롯으로 표시된다. 표시된 잔차의 분포를 보면서 추가로로 통찰력을 키울 수 있다.
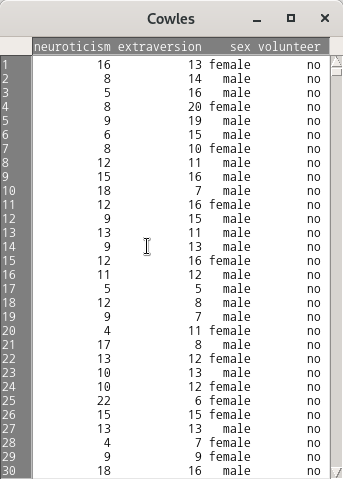
TheCowlesdata frame has 1421 rows and 4 columns. These data come from a study of the personality determinants of volunteering for psychological research.
Usage
Cowles
Format
This data frame contains the following columns:
neuroticism
scale from Eysenck personality inventory
extraversion
scale from Eysenck personality inventory
sex
a factor with levels:female;male
volunteer
volunteeing, a factor with levels:no;yes
Source
Cowles, M. and C. Davis (1987) The subject matter of psychology: Volunteers.British Journal of Social Psychology26, 97–102.
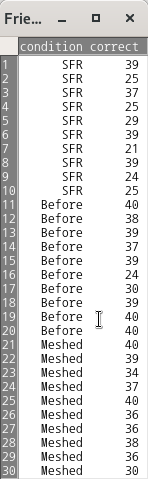
TheFriendlydata frame has 30 rows and 2 columns. The data are from an experiment on subjects' ability to remember words based on the presentation format.
Usage
Friendly
Format
This data frame contains the following columns:
condition
A factor with levels:Before, Recalled words presented before others;Meshed, Recalled words meshed with others;SFR, Standard free recall.
correct
Number of words correctly recalled, out of 40 on final trial of the experiment.
Source
Friendly, M. and Franklin, P. (1980) Interactive presentation in multitrial free recall.Memory and Cognition8265–270 [Personal communication from M. Friendly].
References
Fox, J. (2016)Applied Regression Analysis and Generalized Linear Models, Third Edition. Sage.
Fox, J. and Weisberg, S. (2019)An R Companion to Applied Regression, Third Edition, Sage.