통계 > 비율 > 이-표본 비율 검정...
Statistics > Proportions > Two-sample proportions test...
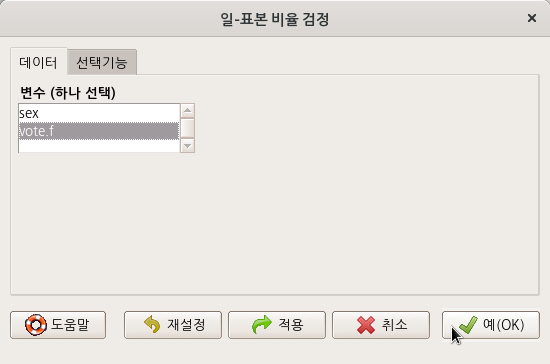
요인형 변수를 두개 이상 가지고 있는 데이터셋이 활성화되어 있다면, '통계 > 비율 > 이-표본 비율 검정..' 메뉴 기능을 이용할 수 있다. carData 패키지에 있는 Chile 데이터셋을 활용해서 연습해보자. 먼저, '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 통하여 Chile 데이터셋을 활성화시키자. R Commander 상단에 'Chile'라는 데이터셋이 활성화되었는지 확인하자.
Chile 데이터셋
carData::Chile() data(Chile, package="carData") '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하면 하위 선택 창으로 이동한다. 아래와 같이 carData 패키지를 선택.
rcmdr.kr
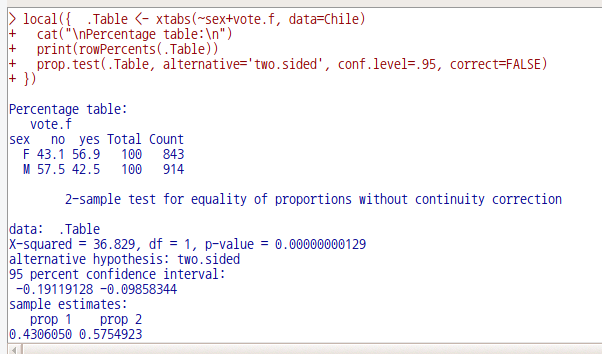
요인형 변수 vote를 변형시켜 vote.f 변수를 새롭게 코딩하고 사용하도록 하자.
data(Chile, package="carData")
Chile <- within(Chile, {
vote.f <- Recode(vote, '"Y" = "yes"; "N" = "no"; else = NA', as.factor=TRUE)
})
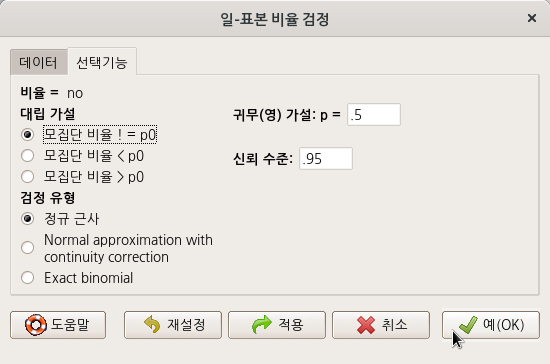
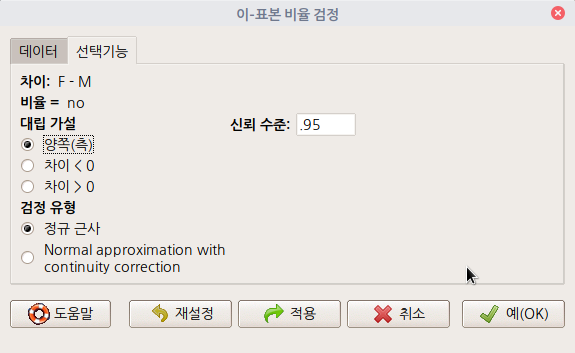
'선택기능' 메뉴 창에서 추천하는 기본설정을 그대로 사용하자.
?prop.test # stats 패키지의 prop.test 도움말 보기1. Recode variables...
데이터 > 활성 데이터셋의 변수 관리하기 > 변수를 다시 코딩하기... Data > Manage variables in active data set > Recode variables... 기존 변수를 이용하여 새로운 변수를 만들 수 있다. R Commander에서 이..
rcmdr.kr
'Statistics > Proportions' 카테고리의 다른 글
| 1. Single-sample proportion test... (0) | 2022.03.12 |
|---|