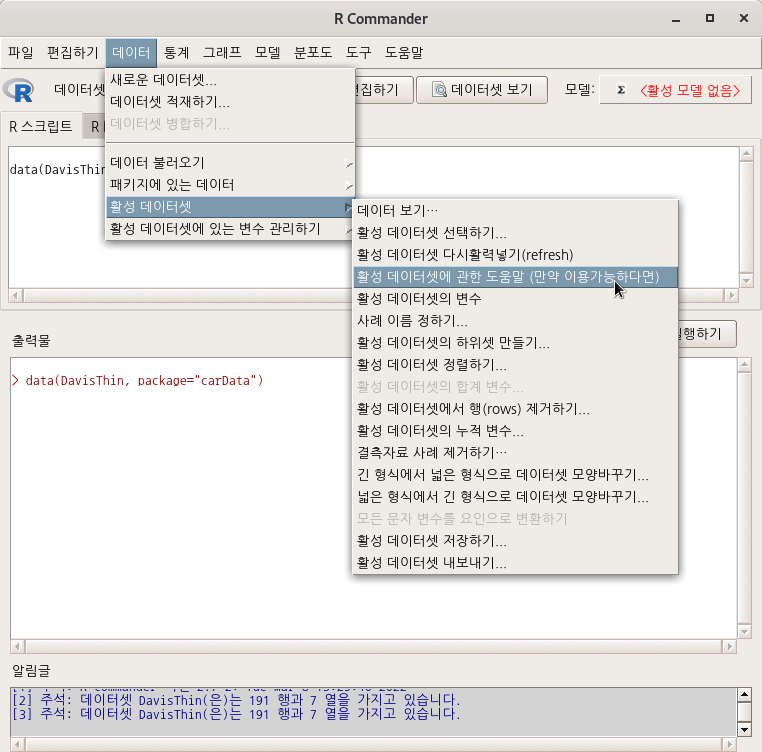
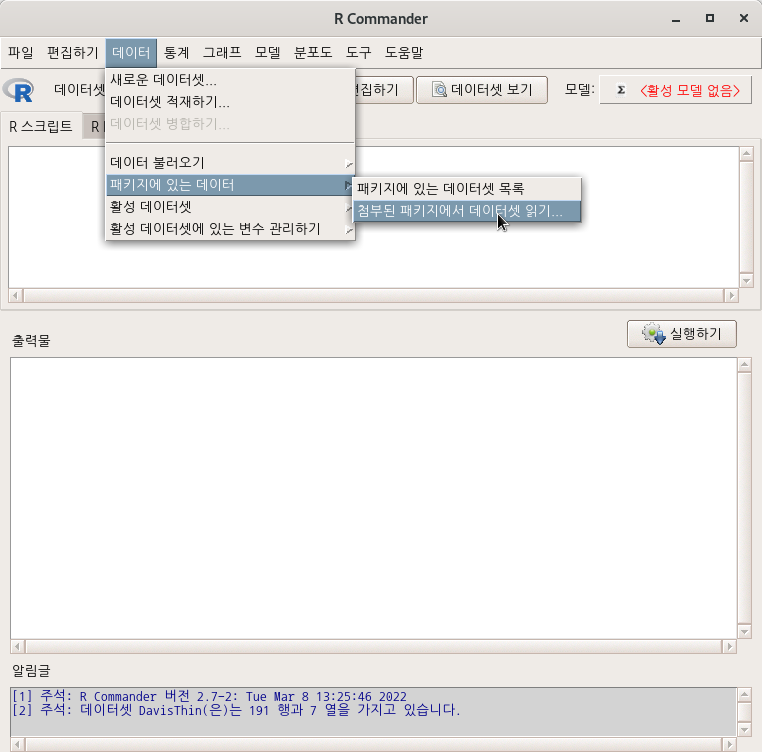
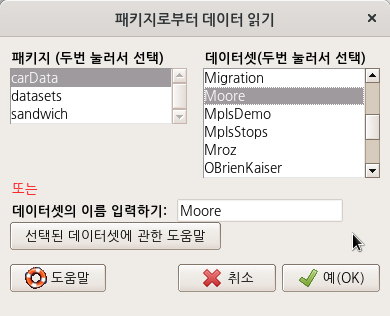
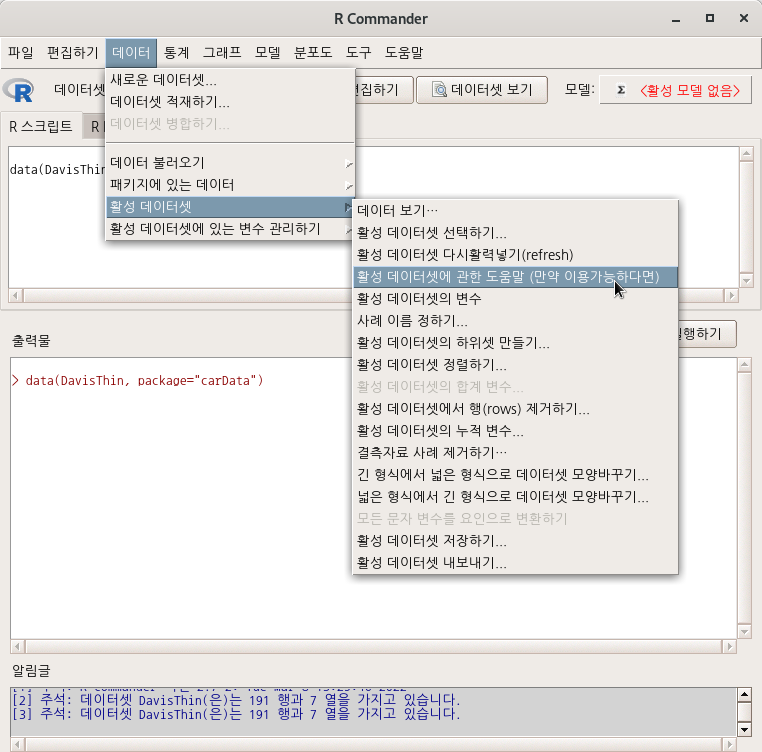
carData::Cowles

data(Cowles, package="carData")
help("Cowles")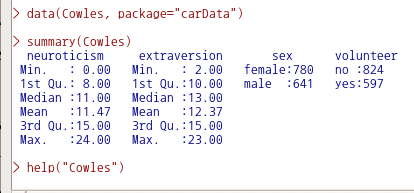
| Cowles {carData} | R Documentation |
Cowles and Davis's Data on Volunteering
Description
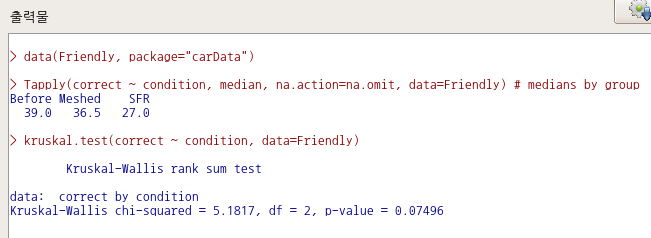
The Cowles data frame has 1421 rows and 4 columns. These data come from a study of the personality determinants of volunteering for psychological research.
Usage
CowlesFormat
This data frame contains the following columns:
neuroticism
scale from Eysenck personality inventory
extraversion
scale from Eysenck personality inventory
sex
a factor with levels: female; male
volunteer
volunteeing, a factor with levels: no; yes
Source
Cowles, M. and C. Davis (1987) The subject matter of psychology: Volunteers. British Journal of Social Psychology 26, 97–102.