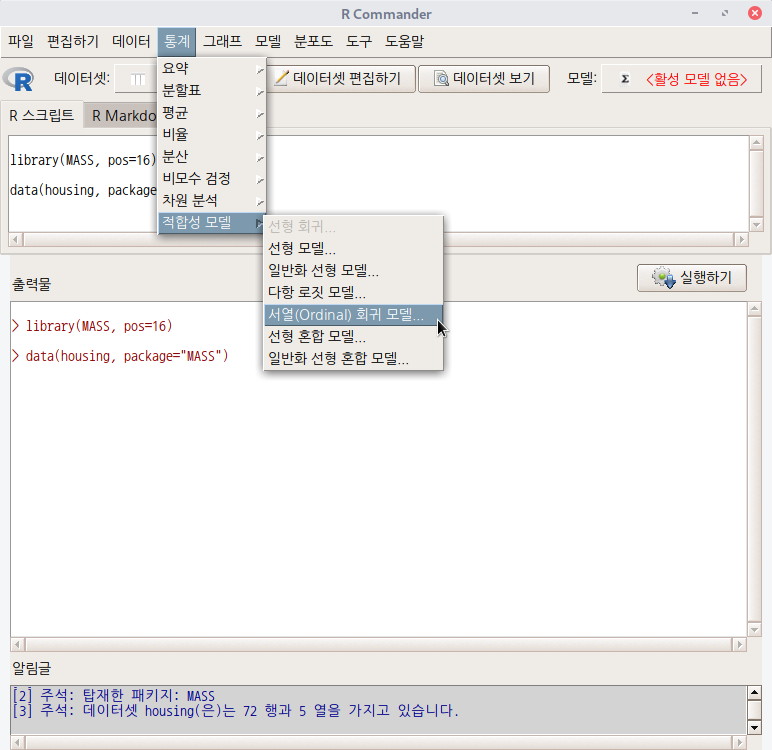
통계 > 적합성 모델 > 일반화 선형 혼합 모델... Statistics > Fit models > Generalized linear mixed model...
Linux 사례 (MX21)
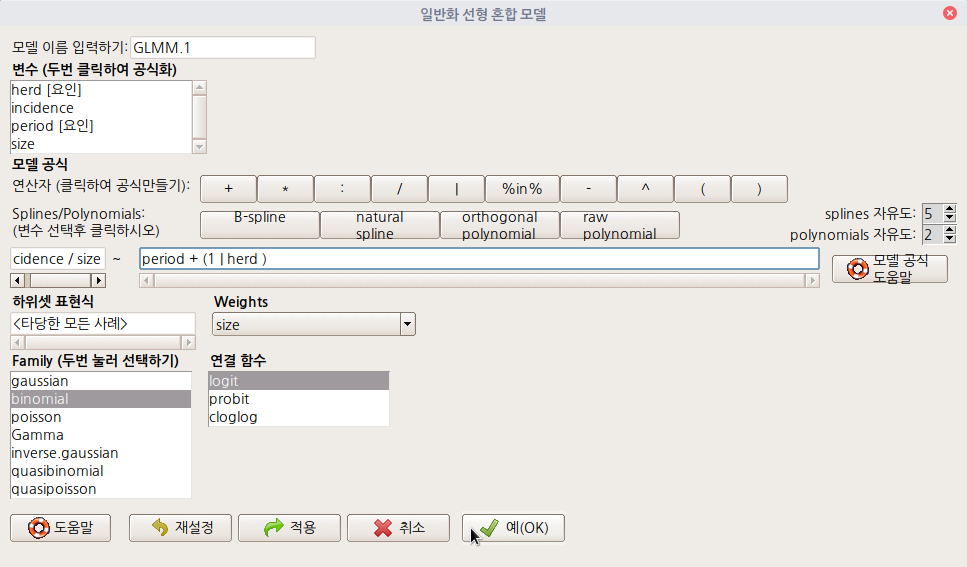
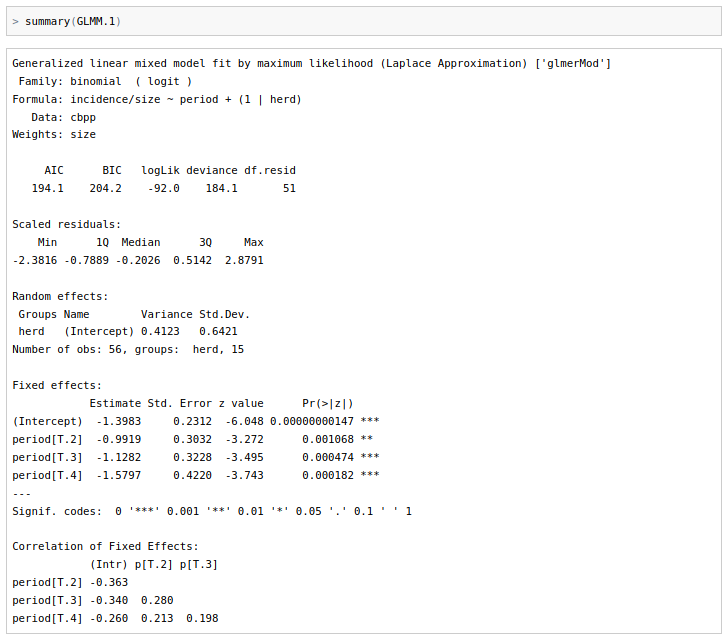
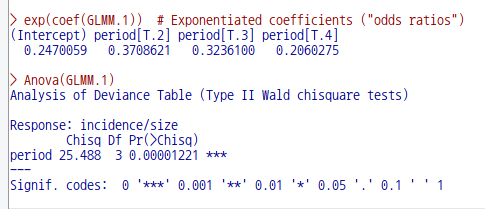
'도구 > 패키지 적재하기...' 메뉴 기능을 이용하여 lme4 패키지를 찾아서 적재하자. lme4 패키지에는 일반화 선형 혼합 모델을 만들고 분석하는데 필요한 glmer()와 예제 데이터셋 cbpp가 포함되어 있다.
'데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 통하여 lme4 패키지에 있는 cbpp 데이터셋을 찾아서 선택하자. 그러면 R Commander의 상단에 있는 <활성 데이터셋 없음>이 'cbpp'로 활성화될 것이다. https://rcmdr.tistory.com/240
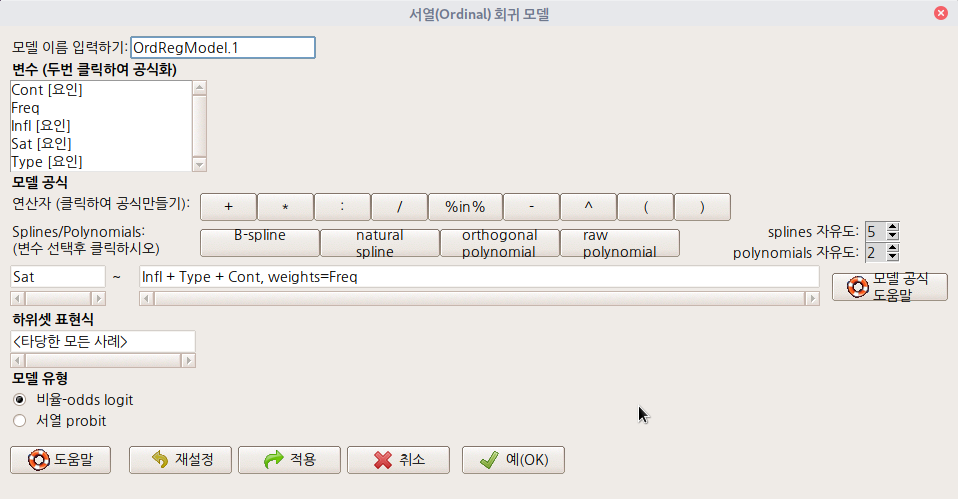
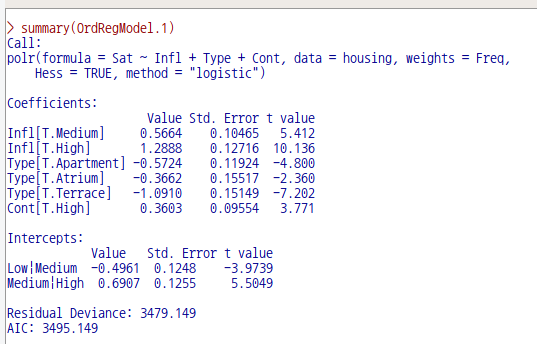
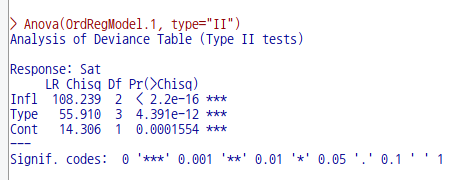
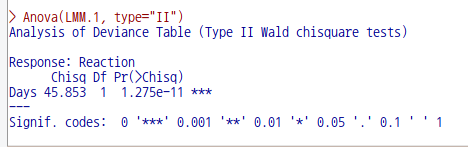
Sat는 거주자의 현 거주환경에 대한 만족도에 관한 변수로서, High > Medium > Low 라는 서열화된 요인을 갖고 있다. Sat를 반응변수로, 나머지를 설명변수의 후보군으로 모델을 구성하는 것이다. Freq 변수는 Sat, Infl, Type, Cont 등으로 구별되는 집단 구성원의 숫자를 뜻한다. 아래와 같이 모형을 만든다.
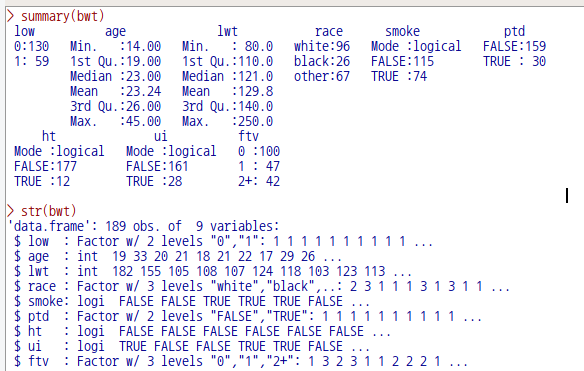
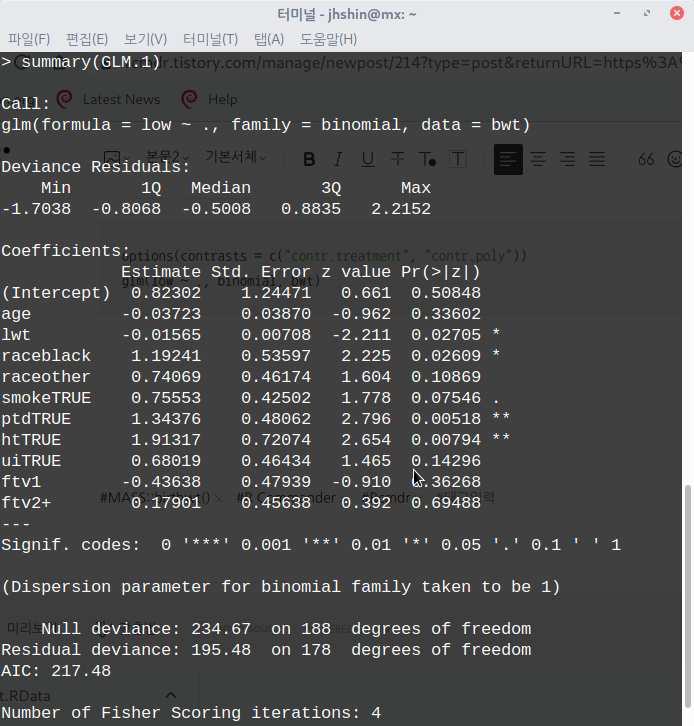
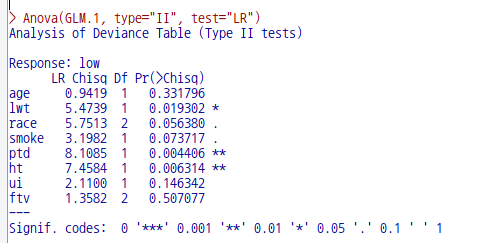
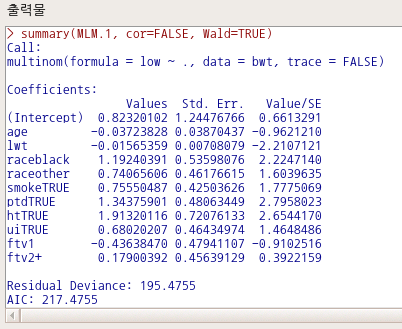
bwt 데이터셋은 분석 모형을 만드는데 간혹 예제로 사용되는데, birthwt에서 bwt가 만들어지는 과정이 R Commander 기본 사용자에게는 다소 어렵게 느껴질수 있겠다는 판단이다. 데이터셋 자체에 대한 이해의 어려움 때문에 분석 모형의 구성과 해석으로 나아가지 못하는 경우가 있어, bwt 데이터셋 설명을 하고자 한다.
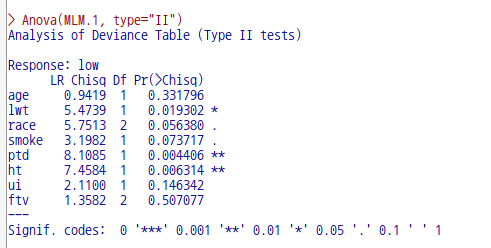
bwt 데이터셋은 저체중아 출생의 원인을 찾고자 하는 문제의식을 담고 있다. low 변수는 출생당시 몸무게가 2.5kg 미만 여부를 담고 있으며, 반응변수가 된다. 나머지 변수들은 저체중아 출산에 영향을 끼치는가 여부인 설명변수들의 후보군이 되겠다.
통계 > 적합성 모델 > 선형 혼합 모델... Statistics > Fit models > Linear mixed model...
Linux 사례 (MX 21)
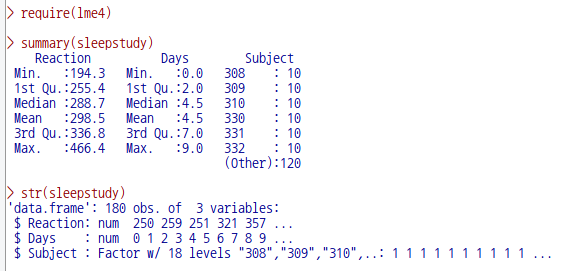
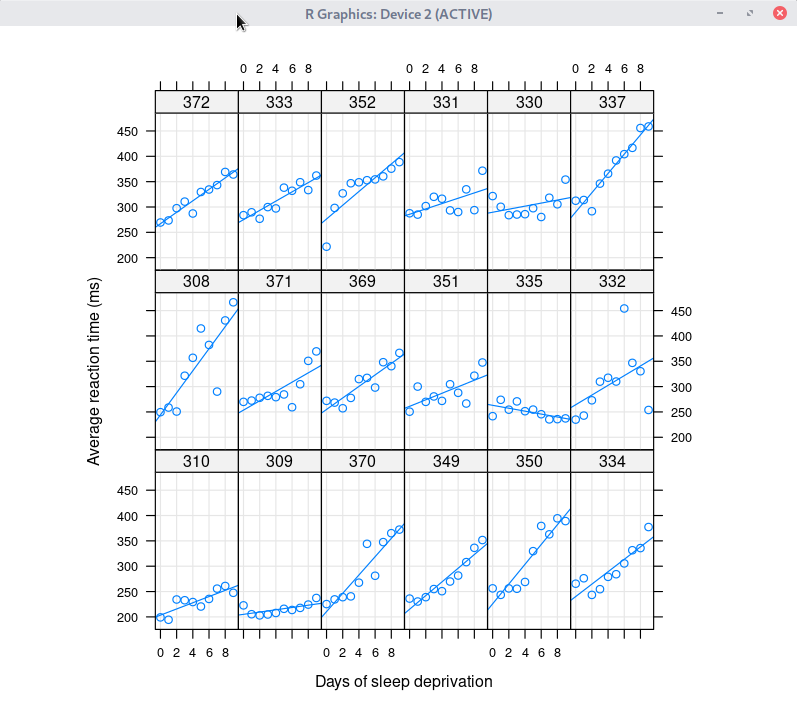
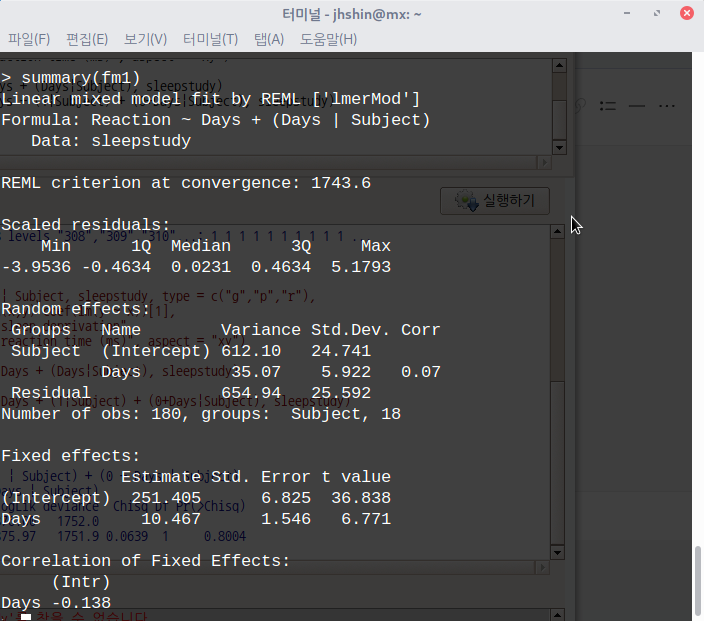
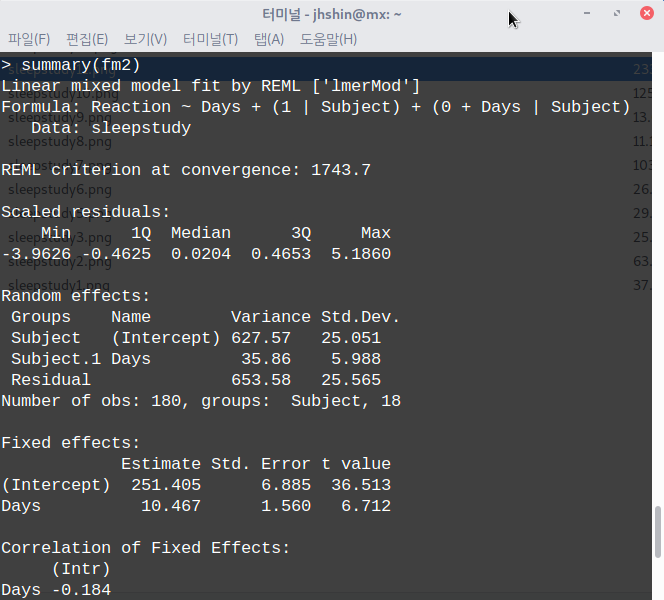
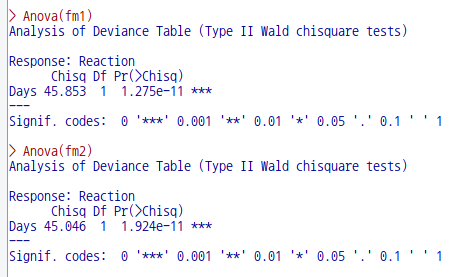
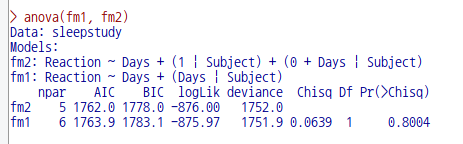
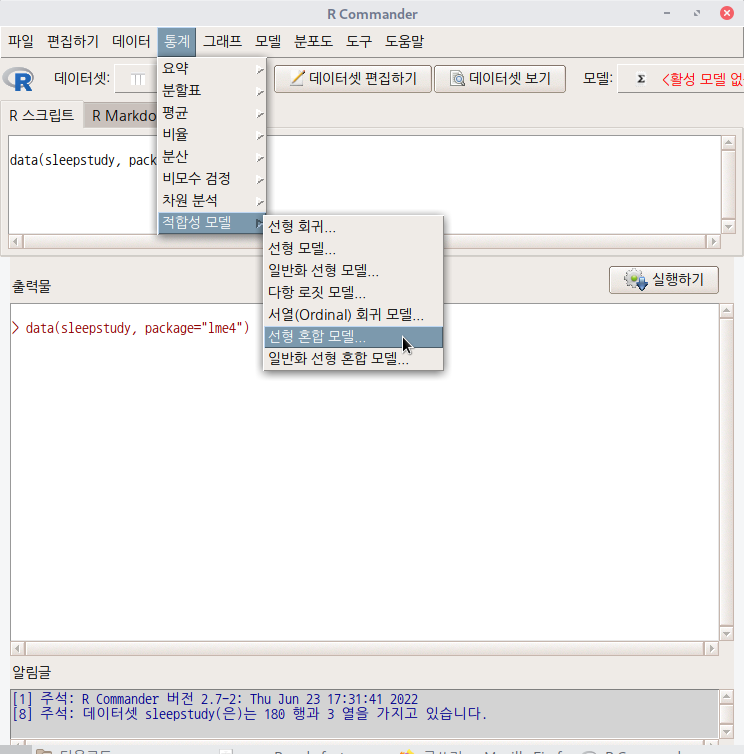
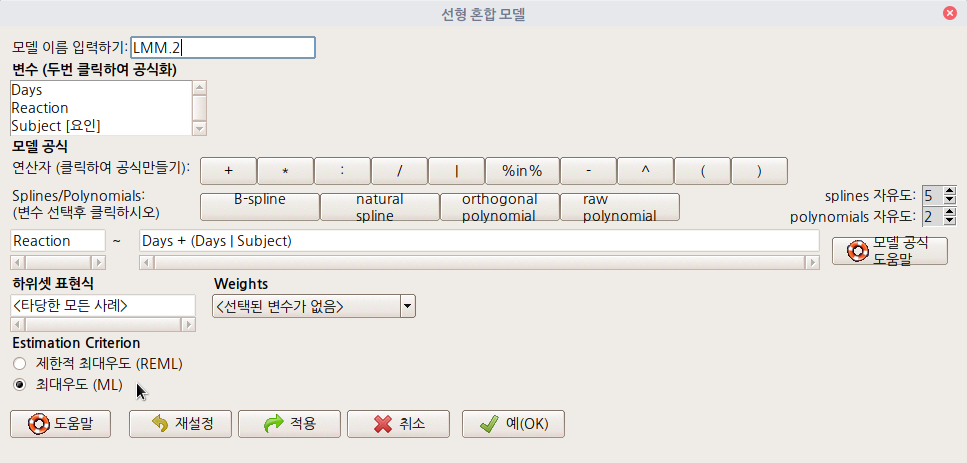
데이터셋을 활성화시키면, '통계 > 적합성 모델 > 선형 혼합 모델...' 메뉴 기능을 사용할 수 있다. lme4 패키지의 sleepstudy 데이터셋을 이용하여 연습해보자.
sleepstudy 데이터셋을 활성화 시키자. 먼저 lme4 패키지를 호출해야 한다. 그래야 포함된 데이터셋 목록을 확인할 수 있기 때문이다. '도구 > 패키지 적재하기...' 메뉴 기능을 통하여 lme4를 적재한다. 그리고 '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...' 메뉴 기능을 선택하고, 다음 화면에서 lme4 패키지에 포함된 데이터셋들 중에서 sleepstudy를 찾아서 선택한다. 그러면, R Commander 상단의 <활성 데이터셋 없음> 버튼이 'sleepstudy'로 바뀐다.