데이터 > 활성 데이터셋의 변수 관리하기 > 변수 표준화하기...
Data > Manage variables in active data set > Standardize variables...

활성데이터셋에 있는 수치형 변수들은 서로 다른 기준의 값들을 가질 것이다. 정수형 값도 있을 수 있다. 크기도 다를 수 있다. 만약 크기와 기준이 다른 수치형 변수들을 결합해서 분석 작업을 진행할 경우, 영향력 순위를 확인하는데 불편할 수 있다.
예를 들어서, 시험과목 중에서 어느 것이 난이도가 높은가를 알려면 평균점수를 확인할 것이고, 같은 점수라 하더라도 어느 과목점수가 더 높은가를 확인하려면, 이른바 상대평가를 하려면 척도 계산을 해야할 것이다. 변수 표준화하기는 척도 함수를 사용하여 상대화된 기준으로 사례 값을 재조정하는 기능이다. 대화창에서 수치형 변수를 선택하고 변수를 표준화하면, 기존의 변수명 앞에 Z가 붙는, Z.변수라는 새로운 표준화 값을 갖는 변수가 생성된다.
Prestige 데이터셋에서 교육연수(education)와 수입(income)이 직업의 권위에 대한 사회적 인식(prestige)에 어떤 영향을 미치는가에 대한 문제의식에 대한 통계학적 접근을 위하여 세개의 수치형 변수를 표준화하려고 한다.
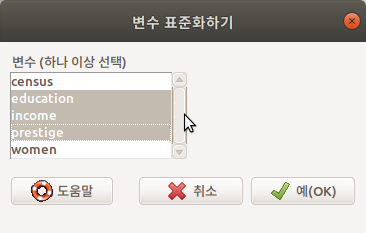
Prestige <- local({
.Z <- scale(Prestige[,c("education","income","prestige")])
within(Prestige, {
Z.prestige <- .Z[,3]
Z.income <- .Z[,2]
Z.education <- .Z[,1]
})
})R Commander에 있는 <데이터셋 보기> 버튼을 눌러 Prestige 데이터셋의 내부를 살펴보자. Z.prestige, Z.income, Z.education 이라는 세개의 변수가 생성되었음을 알 수 있다.

?scale # base 패키지의 scale 도움말 보기
require(stats)
x <- matrix(1:10, ncol = 2)
(centered.x <- scale(x, scale = FALSE))
cov(centered.scaled.x <- scale(x)) # all 1'Data > Manage variables in active data set' 카테고리의 다른 글
| 7. Bin a numeric variable... (0) | 2020.03.21 |
|---|---|
| 5. Convert numeric variable to factor... (0) | 2020.03.18 |
| 3. Add observation number to data set (0) | 2019.09.08 |
| 2. Compute new variable... (0) | 2019.09.08 |
| 1. Recode variables... (0) | 2019.09.08 |