모델 > 부트스트랩 신뢰 구간...
Models > Bootstrap confidence intervals...
'모델 > 신뢰구간...'메뉴 기능을 carData 패키지에 있는 Prestige 데이터셋을 이용하여 연습해보자. 먼저 '데이터 > 패키지에 있는 데이터 > 첨부된 패키지에서 데이터셋 읽기...'메뉴 기능을 통하여 Prestige 데이터셋을 불러온다.
Prestige 데이터셋
carData > Prestige data(Prestige, package="carData") help("Prestige") Prestige {carData} R Documentation Prestige of Canadian Occupations Description The Prestige data frame has 102 rows and 6 col..
rcmdr.kr
data(Prestige, package="carData")
LinearModel.1 <- lm(prestige ~ education + income + education:income, data=Prestige)
summary(LinearModel.1)교육(education)과 수입(income)이라는 설명변수의 조합으로 직업의 사회적 권위(prestige)에 대한 선형모형, LinearModel.1을 만들었다. LinearModel.1의 요약 정보는 아래와 같다.
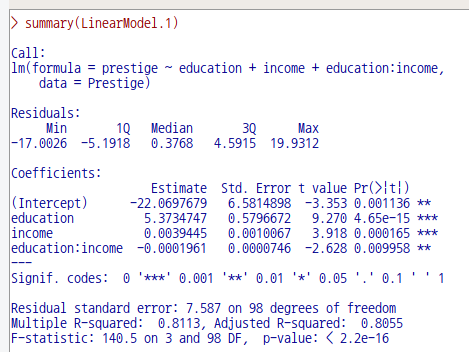
LinearModel.1의 계수(Coefficients) 정보에는 투입된 설명변수들의 영향력에 대한 추정치(Estimate)가 있다. '모델 > 부트스트랩 신뢰 구간...'은 반복 측정 기법을 이용하여 추정치를 계산한다.
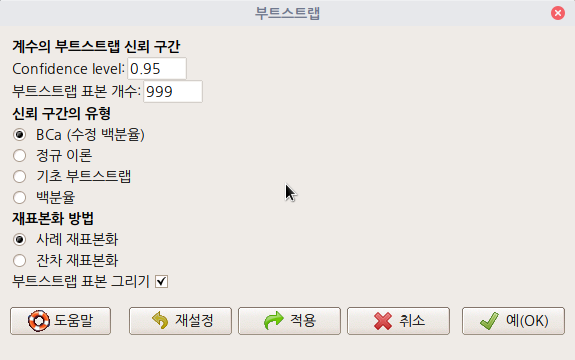
부트스트랩 메뉴 창에는 여러개의 선택 기능이 있다. 기본설정으로 추천되는 항목들을 그대로 유지한채 예(OK) 기능을 선택해보자.
.bs.samples <- Boot(LinearModel.1, R=999, method="case")
plotBoot(.bs.samples)
confint(.bs.samples, level=0.95, type="bca")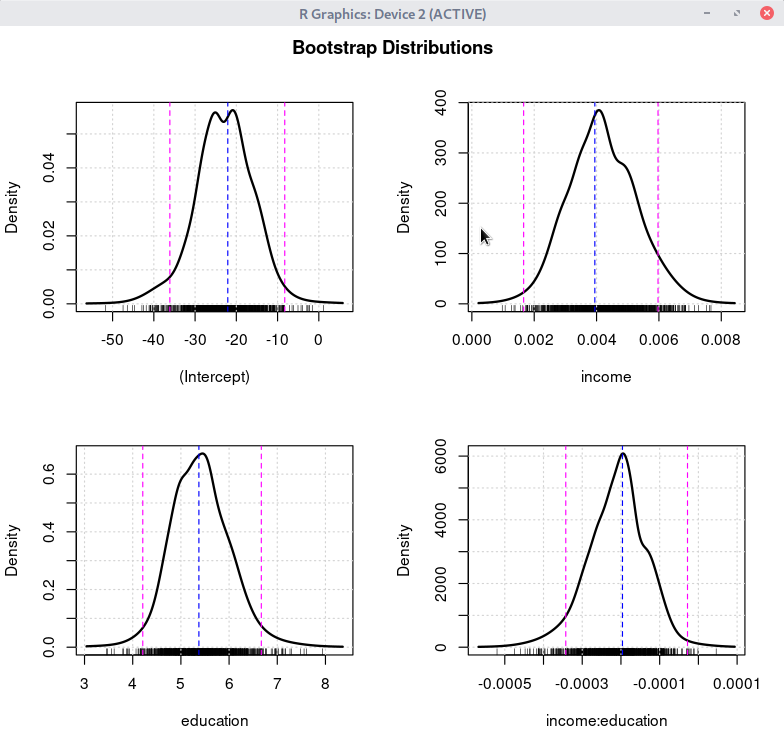

'모델 > 부트스트랩 신뢰 구간...'메뉴 바로 위에 '모델 > 신뢰 구간...'메뉴 기능이 있다. 이 때 쓰이는 함수가 위의 출력물 결과창에서 보는 것처럼 Confint()이다. '부트스트랩 신뢰 구간...' 기능은 신뢰 구간을 구하는 Confint()함수에 LinearModel.1을 바로 객체로서 사용하는 것이 아니라, 위에 화면 상단에서 보듯이 .bs.samples를 객체로 사용한다. .bs.samples라는 객체는 Boot()를 사용하여 만들어진다. Boot()는 LinearModel.1 모형을 활용하여 필요한 정보를 추출하는데, 1번의 분석이 아닌 'R=999' 처럼 999회 반복 추출을 한다. 이 과정은 과거 컴퓨터의 성능이 낮을 때는 매우 많은 시간을 요구하는 기능이었으나, 컴퓨터 성능의 향상으로 시간이 많이 단축되었다.
그렇다면, 왜 'R=999'처럼 반복 추출을 통한 분석을 999회 실시하여 방대한 분석 자료를 만들까. 자료는 일반적으로 제한된 사례수에 의하여, 또는 이론적인 분포를 적용하기 어려운 불규칙한 특징을 갖기가 쉽다. 규칙을 정한 반복 추출 과정을 통한 분석 결과가 일정한 패턴을 갖기를 기대하면서 보다 이론적 분포에 가깝거나, 1회적 분석 결과가 갖는 오류 가능성을 축소시키고자 하는 목적으로 부트스크랩 기법을 사용하게 된다.
위의 출력물에서 Confint()의 객체를 LinearModel.1을 쓴 경우, .bs.samples를 쓴 경우, 95% 범위내에서 회귀 계수의 범위가 어떤 차이를 보이는지 비교할 수 있을 것이다. 아래 '모델 > 신뢰 구간...' 기능 설명을 참고할 수 있다.
Confidence intervals...
모델 > 신뢰 구간... Models > Confidence intervals... '모델 > 신뢰구간...'메뉴 기능을 carData 패키지에 있는 Prestige 데이터셋을 이용하여 연습해보자. 먼저 '데이터 > 패키지에 있는 데이터 > 첨부된 패키..
rcmdr.kr
?Boot # car 패키지에 있는 Boot 함수 도움말 보기