통계 > 분할표 > 이원표 입력 및 분석하기...
Statistics > Contingency tables > Enter and analyze two-way table...

'통계 > 분할표 > 이원표 입력 및 분석하기...' 메뉴 기능을 선택하면 하위 창이 등장한다. '변수 이름', '행과 열의 수', '사례 수' 등을 입력할 수 있다. 아래의 내용은 'chisq.test' 함수 도움말 문서에 나오는 사례를 입력한다. 아래의 입력 스크립트를 참조 할 수 있다.
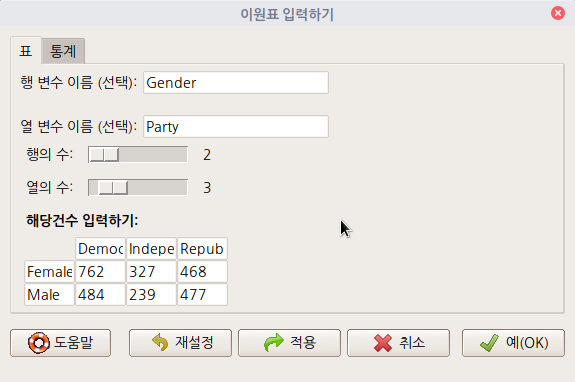

.Table <- matrix(c(762,327,468,484,239,477), 2, 3, byrow=TRUE)
dimnames(.Table) <- list("Gender"=c("Female", "Male"), "Party"=c("Democrats", "Independent",
"Republican"))
.Table # Counts
.Test <- chisq.test(.Table, correct=FALSE)
.Test
.Test$expected # Expected Counts
?chisq.test # stats 패키지의 chisq.test 도움말 보기
## From Agresti(2007) p.39
M <- as.table(rbind(c(762, 327, 468), c(484, 239, 477)))
dimnames(M) <- list(gender = c("F", "M"),
party = c("Democrat","Independent", "Republican"))
(Xsq <- chisq.test(M)) # Prints test summary
Xsq$observed # observed counts (same as M)
Xsq$expected # expected counts under the null
Xsq$residuals # Pearson residuals
Xsq$stdres # standardized residuals
## Effect of simulating p-values
x <- matrix(c(12, 5, 7, 7), ncol = 2)
chisq.test(x)$p.value # 0.4233
chisq.test(x, simulate.p.value = TRUE, B = 10000)$p.value
# around 0.29!
## Testing for population probabilities
## Case A. Tabulated data
x <- c(A = 20, B = 15, C = 25)
chisq.test(x)
chisq.test(as.table(x)) # the same
x <- c(89,37,30,28,2)
p <- c(40,20,20,15,5)
try(
chisq.test(x, p = p) # gives an error
)
chisq.test(x, p = p, rescale.p = TRUE)
# works
p <- c(0.40,0.20,0.20,0.19,0.01)
# Expected count in category 5
# is 1.86 < 5 ==> chi square approx.
chisq.test(x, p = p) # maybe doubtful, but is ok!
chisq.test(x, p = p, simulate.p.value = TRUE)
## Case B. Raw data
x <- trunc(5 * runif(100))
chisq.test(table(x)) # NOT 'chisq.test(x)'!'Statistics > Contigency tables' 카테고리의 다른 글
| 2. Multi-way tables... (0) | 2022.06.28 |
|---|---|
| Contingency tables (0) | 2022.02.14 |
| 1. Two-way table... (0) | 2022.02.14 |







