그래프 > 밀도 추정...
Graphs > Density estimate...

밀도 그래프(densityplot)은 수치형 변수를 촘촘히 배열하면서 그 사례사이의 거리를 역으로 밀도화시키는 방법이다. 줄여 말하면, 거리가 가까우면 밀도가 높고, 거리가 멀면 밀도가 낮게 계산되고 시각화된다. Prestige 데이터셋의 income 변수를 사용해보자.

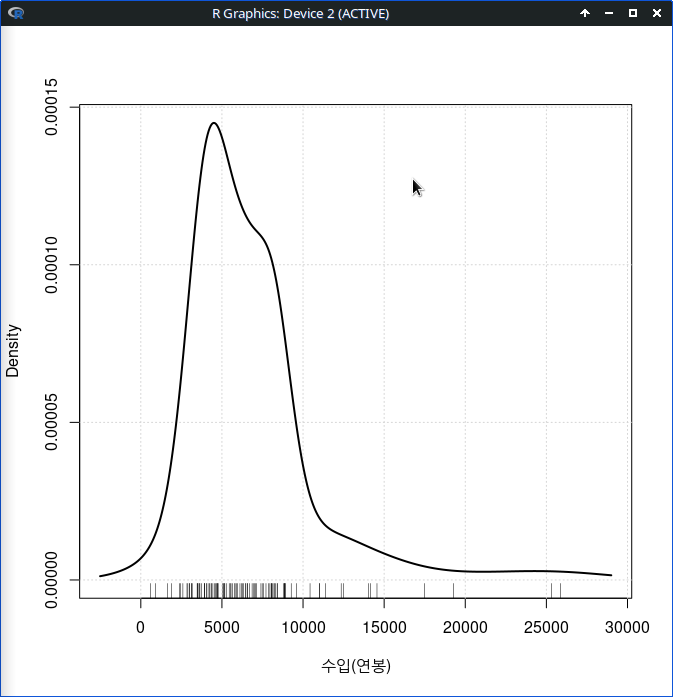
밀도 추정 그래프를 시각화하는 경우, 그래프의 시작점과 끝점에 대한 사전정보를 수치적 정보 요약 등을 활용하여 미리 알고서 지정해주면 그래프가 보다 정교해진다. 위의 그래프를 보라. 수입(연봉)을 표시하는 촘촘한 사례들의 영역 바깥에 그래프의 왼쪽 긑과 오른쪽 끝이 표시된 것을 보게된다. 변화를 줘보자.
numSummary(Prestige[,"income", drop=FALSE],
statistics=c("mean", "sd", "IQR", "quantiles"), quantiles=c(0,.25,.5,.75,1))numSummary() 함수를 활용하여 최소값, 최대값 등을 찾아보자. 그 사례 값을 아래의 입력창에 넣는다.
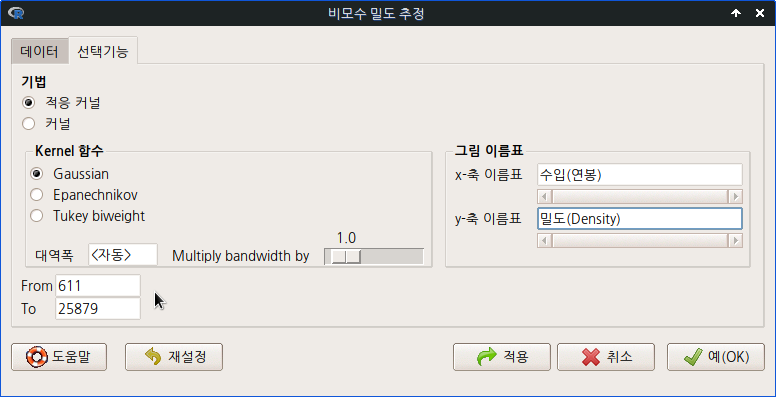
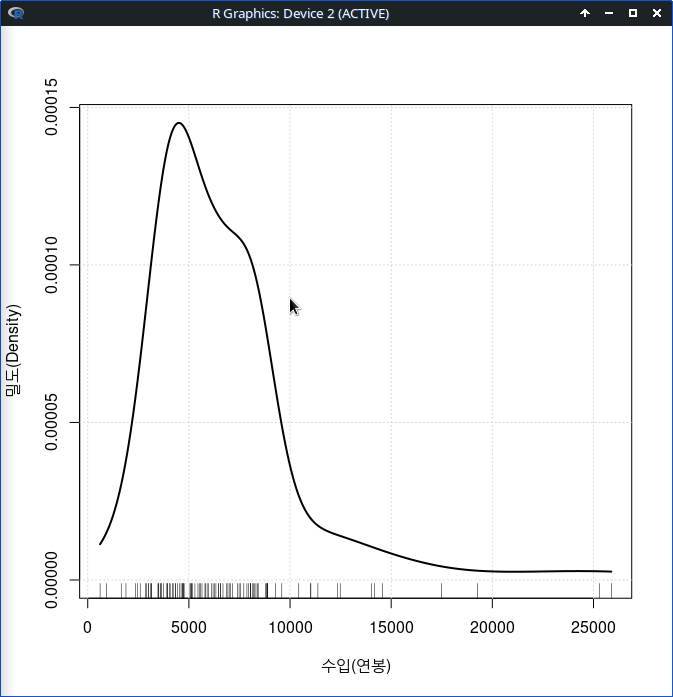
그래프의 시작점에 최소값을, 끝점에 최대값을 넣고 그래프를 만들면, 수입(연봉)의 분포가 보다 분명하게 보일 것이다.
densityPlot( ~ income, data=Prestige, bw=bw.SJ, adjust=1, kernel=dnorm,
method="adaptive", from=611, to=25879, xlab="수입(연봉)", ylab="밀도(Density)").
한편, 직업유형인 요인형 변수 type을 기준으로 수입(연봉)의 분포를 재분류해보자. <집단 기준으로 그리고...> 버튼을 누르면 <집단 변수 (하나 선택)> 기능에서 요인형 변수 목록이 나타날 것이다. Prestige 데이터셋에는 type 하나만 있다. 그리고 예(OK) 버튼을 누른다.

그러면 <집단 기준으로 그리기...> 버튼이 <Plot by: type>으로 바뀐다. type의 수준별로 income의 밀도 분포를 시각화할 준비가 된 것이다.

그래픽장치 창에 type 별 수입(연봉)에 대한 밀도 그래프가 등장한다. 그래프의 오른쪽에는 네모상자 안에 범례 표시가 있어서 어떤 선이 요인형 변수의 어떤 수준을 나타내는지 알려준다.

그래프 > 그래프를 파일로 저장하기 > PDF/Postscript/EPS(으)로 에서 PDF 파일로 저장해보자. 넓이와 높이에 대한 조정 없이<글 크기 (점)>을 16까지 키워보자.

아래 코드에서 'main'인자를 살펴보라. 메뉴창에 등장하는 기능을 활용하면서 적용할 수 있는 범위에 DensityPlot 함수에는 제목 입력이 없다. 아쉽기도 한 부분이다. 이 경우는 입력창에서 main="제목 이름"을 추가하여 넣고 실행하기 버튼을 누르면 된다.
densityPlot(income~type, data=Prestige, bw=bw.SJ, adjust=1, kernel=dnorm,
method="adaptive", from=611, to=25879, xlab="수입(연봉)", ylab="밀도(Density)",
main="1971년 캐나다 직업 유형별 수입에 관한 밀도그래프")
Q1> 첨부된 PDF 파일에는 제목과 축에 사용된 한글이 보이지 않고 점(...)으로 표시됩니다. 고쳐주세요.
?densityPlot # car 패키지의 densityPlot 도움말 보기
densityPlot(~ income, show.bw=TRUE, method="kernel", data=Prestige)
densityPlot(~ income, show.bw=TRUE, data=Prestige)
densityPlot(~ income, from=0, normalize=TRUE, show.bw=TRUE, data=Prestige)
densityPlot(income ~ type, data=Prestige)
densityPlot(~ income, show.bw=TRUE, method="kernel", data=Prestige)
densityPlot(~ income, show.bw=TRUE, data=Prestige)
densityPlot(~ income, from=0, normalize=TRUE, show.bw=TRUE, data=Prestige)
densityPlot(income ~ type, kernel=depan, data=Prestige)
densityPlot(income ~ type, kernel=depan, legend=list(location="top"), data=Prestige)
plot(adaptiveKernel(UN$infantMortality, from=0, adjust=0.75), col="magenta")
lines(density(na.omit(UN$infantMortality), from=0, adjust=0.75), col="blue")
rug(UN$infantMortality, col="cyan")
legend("topright", col=c("magenta", "blue"), lty=1,
legend=c("adaptive kernel", "kernel"), inset=0.02)
plot(adaptiveKernel(UN$infantMortality, from=0, adjust=0.75), col="magenta")
lines(density(na.omit(UN$infantMortality), from=0, adjust=0.75), col="blue")
rug(UN$infantMortality, col="cyan")
legend("topright", col=c("magenta", "blue"), lty=1,
legend=c("adaptive kernel", "kernel"), inset=0.02)