Statistics > Dimensional Analysis > Cluster Analysis > Add hierarchical clustering to data set...
Linux 사례 (MX 21)
' 통계 > 차원 분석 > 군집 분석 > 위계 군집 분석...' 기능을 진행했다고 하자. 그 다음에 <위계군집화를 데이터 셋에 추가하기...>를 이용할 수 있다. <군집의 수:>를 3으로 변경하자. 그리고 예(OK) 버튼을 누르면, hclus.label라는 변수가 USArrests 데이터셋에 추가된다.
Linux 사례 (MX 21)
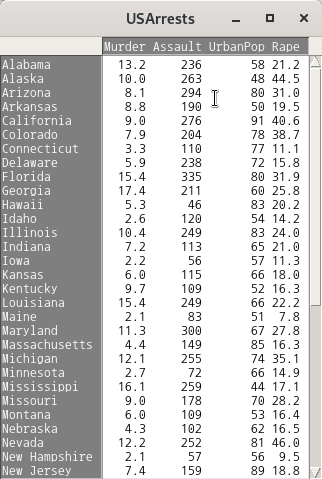
R Commander 상단에 있는 <데이터셋 보기> 버튼을 눌러보자. 아래와 같이 데이터셋의 내부 구성이 보일 것이다. hclus.label 변수가 추가되어 있음을 확인할 수 있다:
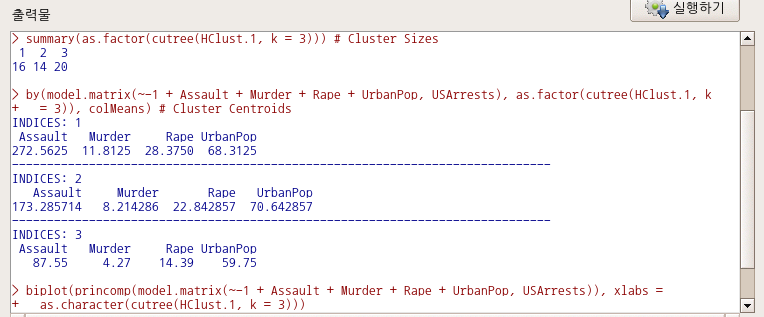
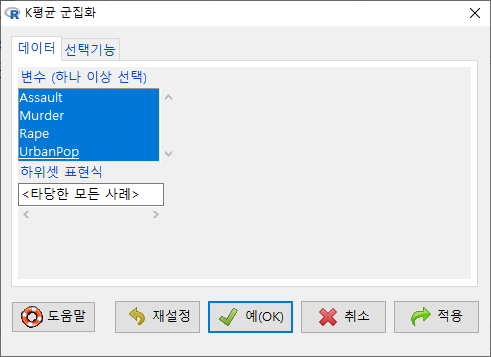
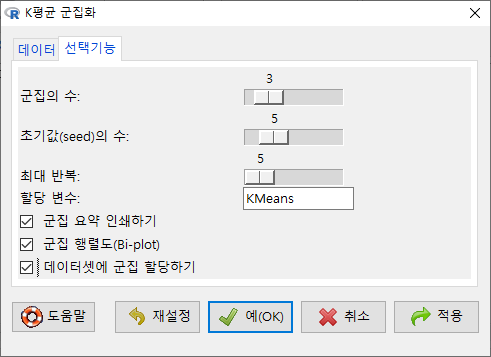
<선택기능> 창에서, 군집의 수를 3개, 초기값의 수를 5번으로, 최대 반복 횟수를 5회로 정해보자. 데이터셋에 추가될 변수 이름이 KMeans가 될 것이다. 아래 있는 선택사항에서 데이터셋에 군집 할당하기를 선택한다.
Windows 사례 (10 Pro)
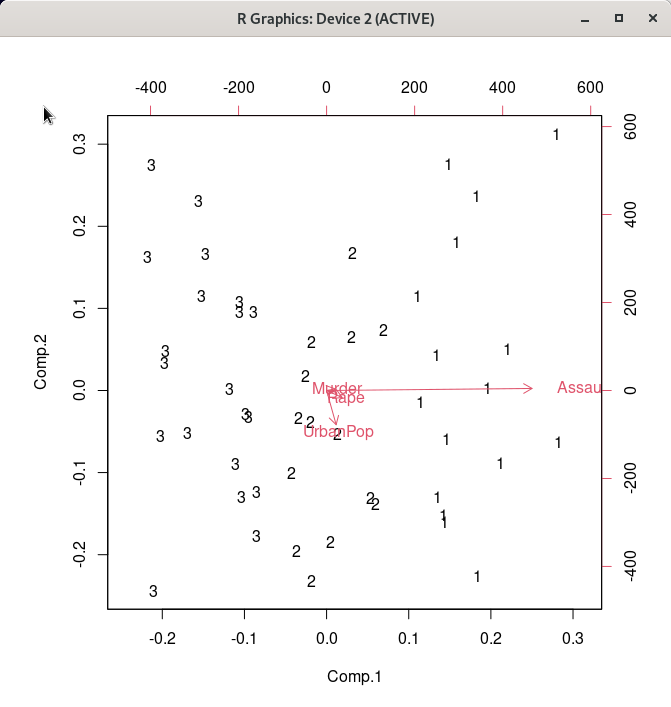
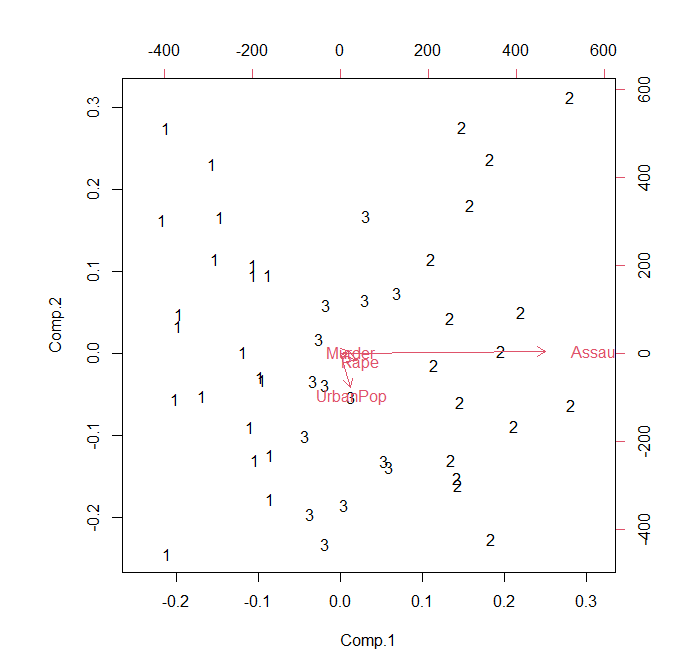
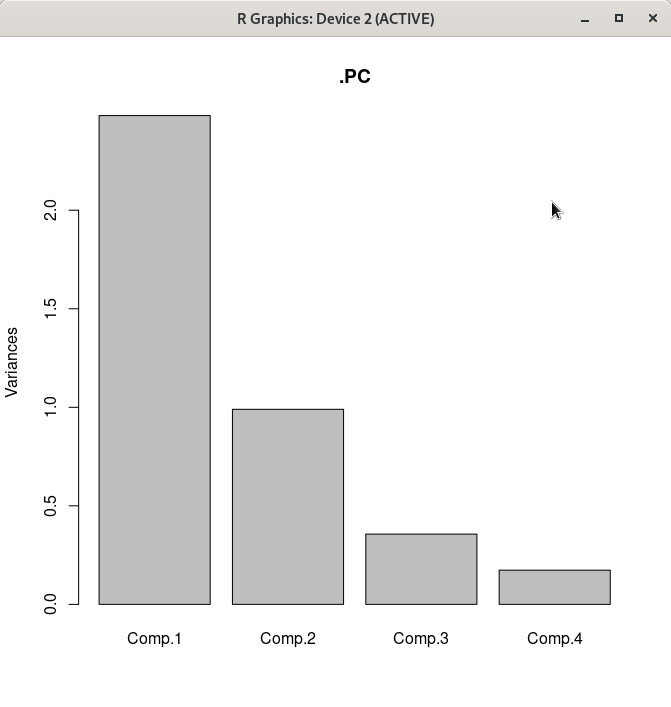
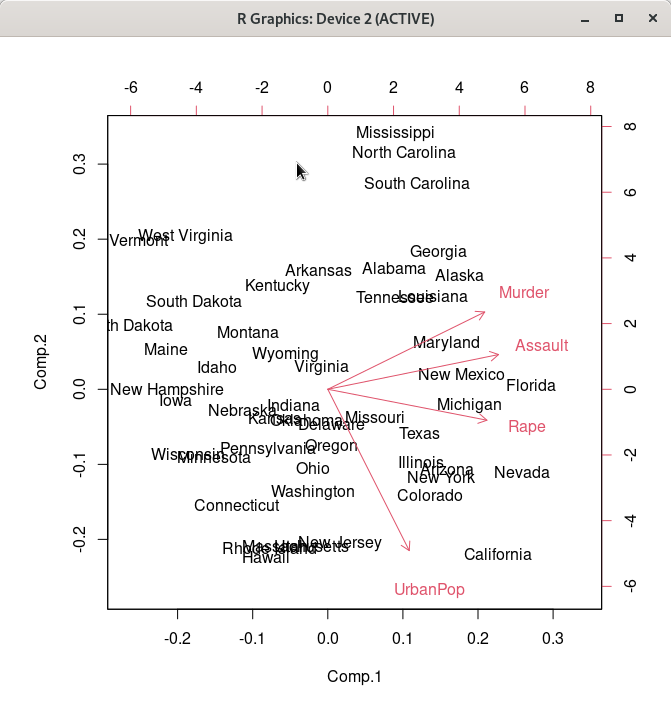
위 화면에서 선택된 군집 행렬도(Bi-plot)이 아래와 같이 생산된다.
Windows 사례 (10 Pro)
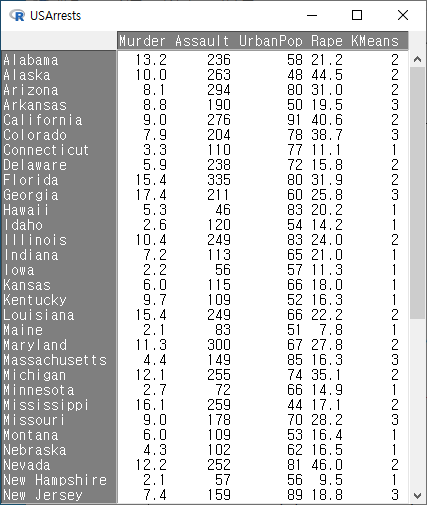
USArrests 데이터셋에 변수 KMeans가 추가될 것이다. R Commander 상단에 있는 <데이터셋 보기> 버튼을 눌러보자. KMeans 변수는 요인형으로 1, 2, 3 이라는 세개의 군집을 표시한다.
Windows 사례 (10 Pro)
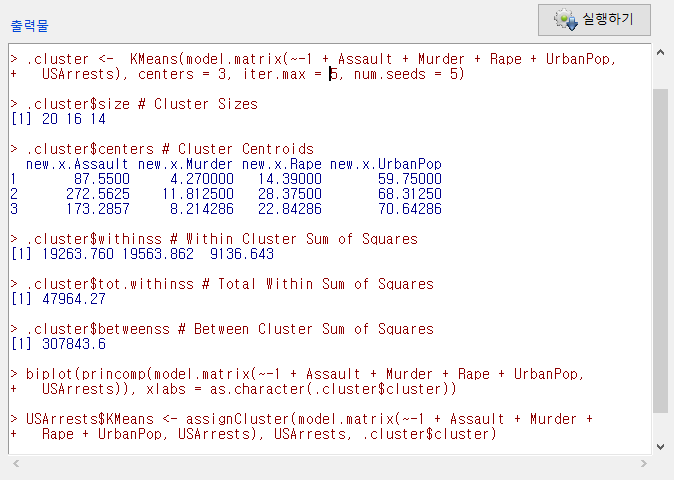
아래 화면은 다소 복잡해보일 것이다. 그러나 객체 .cluster가 만들어졌으며, 그 객체안에 있는 $size, $withinss, $tot.withinss, $betweenss 등의 정보를 차례를 보여준다고 생각하자. 그리고 biplot을 생산하고, USArrests 데이터셋에 KMeans라는 변수를 추가하는 것이다.
R Commander 화면 상단에서 <데이터셋 보기> 버튼을 누르면 아래와 같은 내부 구성을 확인할 수 있다.
Linux 사례 (MX 21)
help("USArrests")
USArrests {datasets}
R Documentation
Violent Crime Rates by US State
Description
This data set contains statistics, in arrests per 100,000 residents for assault, murder, and rape in each of the 50 US states in 1973. Also given is the percent of the population living in urban areas.
Usage
USArrests
Format
A data frame with 50 observations on 4 variables.
[,1]
Murder
numeric
Murder arrests (per 100,000)
[,2]
Assault
numeric
Assault arrests (per 100,000)
[,3]
UrbanPop
numeric
Percent urban population
[,4]
Rape
numeric
Rape arrests (per 100,000)
Note
USArrestscontains the data as in McNeil's monograph. For theUrbanPoppercentages, a review of the table (No. 21) in the Statistical Abstracts 1975 reveals a transcription error for Maryland (and that McNeil used the same “round to even” rule thatR'sround()uses), as found by Daniel S Coven (Arizona).
See the example below on how to correct the error and improve accuracy for the ‘<n>.5’ percentages.
Source
World Almanac and Book of facts 1975. (Crime rates).