모델 > 가설 검정 > 두 모델 비교하기...
Models > Hypothesis test > Compare two models...

하나의 데이터셋을 대상으로 가장 최적의 분석모형을 찾고자 할 때, 또는 보다 정교한 설명을 위하여 만들어진 모형들을 비교하고자 할 때 사용하는 기능이다.
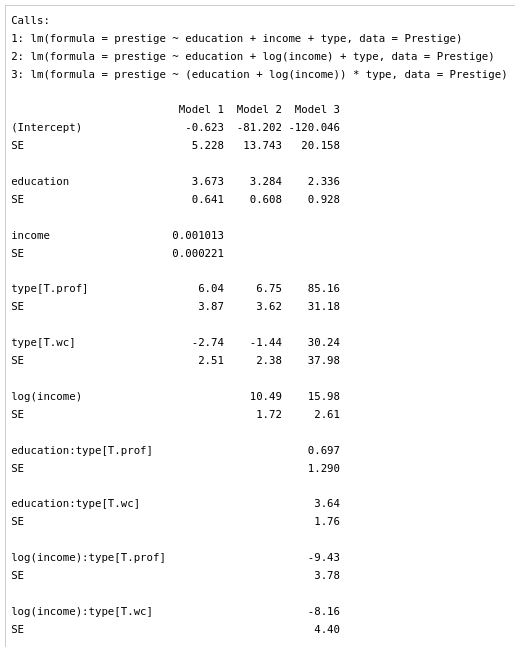
예를 들어, carData에 포함된 Prestige 데이터셋을 이용하여 연습해보자. 직업의 사회적 권위(prestige)에 영향을 미치는 두 개의 독립변수(설명변수)를 교육기간(education)과 수입(income)이라고 가정하자. 그런데 education과 income의 선형적 관계에 대한 보다 깊은 고민을 한다고 생각해보자. education과 income이 서로 독립적인 선형관계로 prestige에 영향을 줄 수도 있고, 또 education과 income이 독립적인 영향을 줄 뿐 만 아니라, 서로 상호작용을 일으키면서 prestige에 영향을 추가 할 수 도 있다고 주장할 수 있다. 이러한 문제의식에서 아래와 같은 두개의 모형을 만들고 또 이 두개의 모형 중에서 어느것이 더 정교한지를 찾는다고 생각해보자.
참고로 연산자 +는 설명변수들의 독립적 선형관계를, *는 독립적 선형관계와 결합적 선형관계를 함께 계산하는데 사용한다.
data(Prestige) #Prestige 데이터셋 불러오기
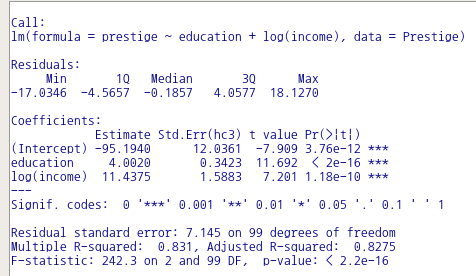
LinearModel.1 <- lm(prestige ~ education + income, data=Prestige #변수들의 독립영향 점검
summary(LinearModel.1)
LinearModel.2 <- lm(prestige ~ education*income, data=Prestige) #변수들의 독립영향 + 결합영향 점검
summary(LinearModel.2)
anova(LinearModel.1, LinearModel.2 #LinearModel.1과 LinearModel.2를 비교하기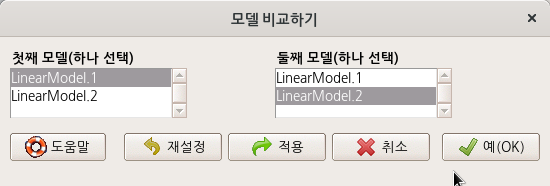
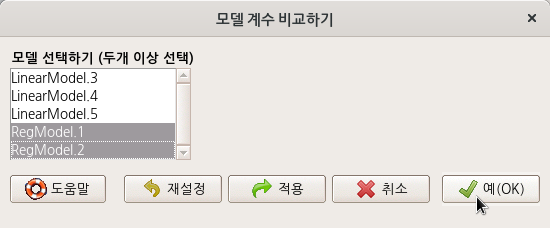
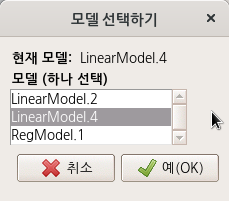
LinearModel.1과 LinearModel.2라는 두 개의 모형을 만들고 두 개의 모델을 비교하는 방법이다. 모델 > 가설 검정 > 두 모델 비교하기...의 메뉴를 선택하면, 만들어 놓은 두 개의 모형을 비교하는 기능을 이용할 수 있다. 직관적으로 두개의 모형을 차례로 선택해보자. 그리고 예(OK) 버튼을 누른다.

R Commander 출력창에 다음과 같은 결과가 출력될 것이다. 출력 내용은 모델 1과 모델 2의 차이가 유의미하며 (Pr(>F)), 모델 2가 보다 설명력이 높다(Sum of sq > 0 또는 RSS < 0)는 뜻으로 해석할 수 있다.
'Models > Hypothesis test' 카테고리의 다른 글
| 1. ANOVA table... (0) | 2022.03.09 |
|---|